
Spark环境配置笔记
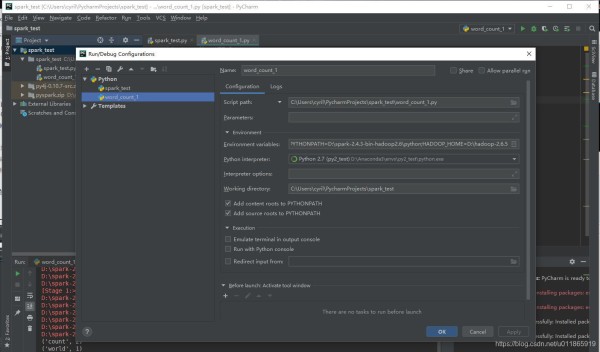
本地Pycharm调试Spark环境配置 Pycharm 首先得装上(尽量别用社区版)Java8/ Python2都安装好(没难度,有问题自行百度)下载Hadoop包/Scala包/Spark-Hadoop包(注意版本对应)不管有用没用先用pip把py4j模块装上。同时pip安装pyspark模块Pycharm中 Run/Debug Configurations -> Environment -> Environment variables: 添加(SPARK_HOME,PYTHONPATH,HADOOP_HOME)三个环境变量PYTHONUNBUFFERED=1;SPARK_HOME=D:\spark-2.4.3-bin-hadoop2.6;PYTHONPATH=D:\spark-2.4.3-bin-hadoop2.6\python;HADOOP_HOME=D:\hadoop-2.6.5
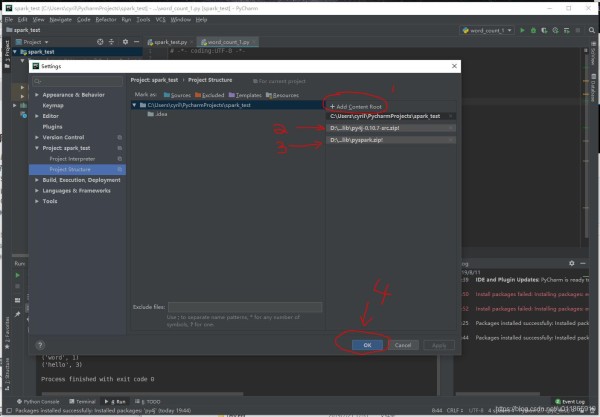
Pycharm中 File -> Project: -> Project Structure -> Add ContentRoot
(依赖库zip包都在spark-hadoop文件夹 /bin 目录下)
 配置完成。 PySpark本地调试遇到的坑 SparkConf的坑
配置完成。 PySpark本地调试遇到的坑 SparkConf的坑初始化SparkContext的代码如下所示:
conf = SparkConf().setAppName("wordcount").setMaster("local") sc = SparkContext(conf) 12
结果报告运行错误:
ERROR SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: Could not parse Master URL: '<pyspark.conf.SparkConf object at 0x0000000002D95908>' 12
根据错误提示,以为是Master的设置有问题,实际上是实例化SparkContext有问题。阅读代码,发现它的构造函数声明如下所示:
def __init__(self, master=None, appName=None, sparkHome=None, pyFiles=None, environment=None, batchSize=0, serializer=PickleSerializer(), conf=None, gateway=None, jsc=None, profiler_cls=BasicProfiler): 123
而前面的代码仅仅是简单的将conf传递给SparkContext构造函数,这就会导致Spark会将conf看做是master参数的值,即默认为第一个参数。所以这里要带名参数:
sc = SparkContext(conf=conf) 1

