R基础学习
数据分析:Python/R基础,学习Pandas和SQL,理解数据可视化工具 #生活技巧# #工作学习技巧# #编程语言学习路径#
这里总结一下,今天老师上课的内容。我觉得跟着老师,我能学到好多东西。我要消化。我突然觉得自己很卑微,因为有那么多东西需要学习的。但是
复习的侧重点在:什么是自己知道的?什么是自己不知道的?缺什么补什么?
identical(a,i) #既检验数值又检验数据类型 i==m 12

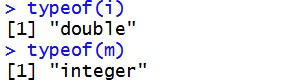
== 仅仅是数值的比较;
identical 则同时包括数值和属性的比较;
df3 <- data.frame(a=1:10, b="character") df3 <- data.frame(a=1:10, b="character", stringsAsFactors=FALSE) 12
stringasFactor等于TRUE或FALSE有何意义?
就是在行列操作的时候,不要把string转换为factor。
(如果发生错误,这个可以作为检查的内容)
方法1:根据行列号
meta.data[4,1] [1] "Stage: 6" 12
*对于data.frame,还可以通过$符号引用每一列。
meta.data$V2 [1] "GSM703914" "A1C" "21PCW" "Stage: 6" #还有,不能直接对data.frame进行转换,需要选择是那一列进行vector转换,尤其是仅有一列的情况要特别注意,否则会报错。 12345
方法2:根据行列名**【这个是我之前不知道的】
meta.data["Stage","V2"] [1] "Stage: 6" 12
注意:(1)如果拿到的是某一行的话,仍旧是一个矩阵。后期分析,要做数据类型转换。(2)如果拿到的是某一列的话,就变成了vector。
(老师提到的这一点是我分析的时候注意到,但是没有细心的去总结的点。)
#对行操作 dim(meta.data[4,]) #变成了1*n列的矩阵 [1] 1 1340 #如果只有一行一列,也会相应的转换成一个vector的 #对列操作 dim(meta.data[,2]) #没有维数了 NULL meta.data[,2] #变成了vector [1] "GSM703915" "AMY" "21PCW" "Stage: 6" 12345678910
注意: data.frame和matrix的区别主要在于:
(1)data.frame可以存储不同的数据类型。
(2)matrix则要求存储的数据类型一致,如果不一致也会强行转为一致。
#两种不同的赋值list的区别:
> l1<-list(1:10) > l2<-as.list(1:10) > l1 [[1]] [1] 1 2 3 4 5 6 7 8 9 10 > l2 [[1]] [1] 1 [[2]] [1] 2 123456789101112
#提取元素:
l2[[10]] #根据序号 [1] 10 l2[["10"]] #根据名字 [1] 10 l2$`10` #使用`$`符号 [1] 10 12345678
在循环的时候,可以使用apply、lappy,sapply函数代替循环,提高运算速率。
R语言高级应用(这个有很多有待补充的地方) (1)sweep()函数:高效处理行列运算的函数sweep(count,2,colSums(data),"\") #解释:对于这个数据的每一列,除以colSums的每一个值。 #这个似乎就是之前我想做的事情 123
上下两个代码等效。
方法1:用传统for循环,需要定义若干中间变量。
sq_line=function(x){sum(x^2)} cellType_sq<-as.data.frame(apply(cellTypeMean2,1,sq_line)) m<-dim(cellTypeMean2)[1] n<-dim(cellTypeMean2)[2] b<-as.data.frame(matrix(,ncol=14,nrow=0)) for(i in 1:m){ a<-c() for (j in 1:n) { SPM_Score<-(cellTypeMean2[i,j])^2/cellType_sq[i,1] a<-append(a, SPM_Score) } b<-rbind(b,a) } colnames(b)<-colnames(cellTypeMean2) cellTypeSPM<-b
12345678910111213141516方法2:直接使用apply和sweep,几行代码搞定。
sq_line=function(x){sum(x^2)} cellType_sq<-as.data.frame(apply(cellTypeMean2,1,sq_line)) cellType_sq2<-as.numeric(cellType_sq$`apply(cellTypeMean2, 1, sq_line)`) sq_2=function(x){x^2} cellTypeMean2_2<-t(apply(cellTypeMean,1,sq_2)) cellTypeSPM2<-sweep(cellTypeMean2_2,1,cellType_sq2,"/") 123456
我学到了!
(2)构建用于绘图的factorSpeciesCols <- c("red", "green") #定义character names(SpeciesCols) <- c("Human", "Macaque") SpeciesColors <- SpeciesCols[plotDat$Species] #这样代码高度值得学习 #用species来定义物种对应的颜色 plot(log2(plotDat$Days), plotDat$SOX11, xlab="Log2(days)", ylab="SOX11", col=SpeciesColors) 1234 (3)match():可以替代传统的subset,直接提取两个数据之间匹配的行
phe[match(bpDat$Sample, phe$Sample),2:15] #提取相同的行 1 (4)melt():在画boxplot的时候,可以取代unstack和stack函数,快捷整理数据的函数
bpDat <- melt(rpkm[,1:20]) 1 (5)用R做PCA:对于PCA得到的值得理解
# PCA # ######## pca <- prcomp(t(rpkm), center=TRUE, scale=TRUE) #使用prcomp函数直接做PCA pcaPlotDat <- cbind(phe, pca$x[,1:2]) ggplot(pcaPlotDat) + geom_point(aes(x=PC1, y=PC2, shape=Species, color=factor(Predicted.period)), size=3) # Note: what does loading mean? pca$rotation[order(pca$rotation[,"PC1"]),1:2][1:30,]#提取第一主成分 pca$rotation[order(pca$rotation[,"PC1"], decreasing=TRUE),1:2][1:30,]#提取第一主成分最接近第一主成分的特征基因 pca$rotation[order(pca$rotation[,"PC2"]),1:2][1:30,] pca$rotation[order(pca$rotation[,"PC2"], decreasing=TRUE),1:2][1:30,] 123456789101112
对比一下,我之前从网上不动脑筋copy的代码,错误在哪里?
#想用一下在课上学到的方法#使用PCA,看看样本整体的特征 com1 <- prcomp(subdata, center = TRUE,scale. = TRUE) test<-as.data.frame(com1$rotation) #我这边错误主要是这里 #我不知道pca计算的各个值是什么意思,把rotation作为要计算的量进行计算了#应该是com1$x的这个矩阵 dim(test) head(test)[1:4,1:4] #到这里PCA的过程是完成了 #xlab<-paste0("PC1(",round(Proportion_of_Variance[1]*100,2),"%)") #ylab<-paste0("PC2(",round(Proportion_of_Variance[2]*100,2),"%)") #绘制散点图 class.label<-as.character(sub.meta.data[2,]) test<-cbind(test,class.label) #这个color的着色策略不知道 library(ggplot2) p1<-ggplot(data = test,aes(x=PC1,y=PC2,color=class.label))+ geom_point() #好像也没出啥大问题,最好是吧aes这些不放在主图的放在geom_point()这个函数这边 p1
12345678910111213141516学到的知识点(主要是对pca计算得到的两个矩阵的理解):
(1)x是计算得到的pca的值的数据矩阵
(2)rotation是一个坐标值,每一个基因距离我们pca抽象得到的这个坐标的距离。距离越小,代表向某一主成分变换的就小,代码其表达值则很有可能作为特征基因分离这些class。
注意在做pca的时候,有一个细节,因为我们想要对样本进行分类,所以需要对数据矩阵进行转置。
#未转置,错误作法 #这里的行,为基因的ID,这就不对,我们想要对样本进行分类 com1 <- prcomp(data, center = TRUE,scale. = TRUE) com1$x[1:5,1:2] PC1 PC2 2315554 4.459692 1.474634 2315633 -5.760801 -5.753679 2315674 13.270301 2.059976 2315739 2.277192 2.812428 2315894 14.307125 -2.800463 #正确做法,需要转置 com2 <- prcomp(t(data), center = TRUE,scale. = TRUE) com2$x[1:5,1:5] PC1 PC2 PC3 PC4 PC5 GSM703914 -41.74332 -28.254455 31.02642 -13.97364 0.0528662 GSM703915 -78.62093 43.049833 23.68928 -27.47652 -19.7426515 GSM703916 -52.34926 -8.689505 -25.94499 -36.08583 14.3021587 GSM703917 -46.36151 -28.822441 55.42635 23.48154 6.7447402 GSM703918 -57.02875 37.377344 15.93358 -19.52037 -15.1469523
1234567891011121314151617181920网址:R基础学习 https://www.yuejiaxmz.com/news/view/400640
相关内容
python基础学习笔记(一)numPyPython机器学习及实践——基础篇11(回归树)
基础护理学
机器学习——线性回归基础
毕业设计:基于机器学习的食物热量卡路里估算方法 人工智能 算法 Faster R
学习网络基础知识的方法
如何正确学习化妆的基础知识
哈工大基础会计学学习视频教程
零基础学习网络安全,注意这几个高效学习方法
基础护理学(一)
随便看看
最新动态分享
- 好设计点亮居家生活!家装沙龙助力业主打造理想家园
- 居家生活设计意图怎么写
- 居家适老化设计:让父母的晚年生活,安全又有温度
- 居家软装布置生活美学设计
- 成都【麓湖生态城C17青鸾屿】售楼电话
- 第三单元 居家生活防意外教学设计
- 我的居家设计花园生活游戏下载
- 成都【银河天悦云境】售楼处电话(最新已核验) | 8月参考总价一览 | 在售主力户型 | 优惠活动详情 | 特价房源 | 楼盘信息更新
- 《2026小红书年度居住趋势》发布:居住方式进入“适我时代”
- Decor Life
热点动态分享
- 145140
- 52622
- 45165
- 42530
- 40973
- 30942
- 25791
- 25551
- 21947
- 18685

