神经网络与Cosine相似度
深度学习入门:理解神经网络基础 #生活技巧# #学习技巧# #深度学习技巧#
概述一些神经网络的论文的观点与数学解释引导了写这篇文章的想法。这篇文章主要是个人的浅见与论文阅读总结。
神经网络的基础数学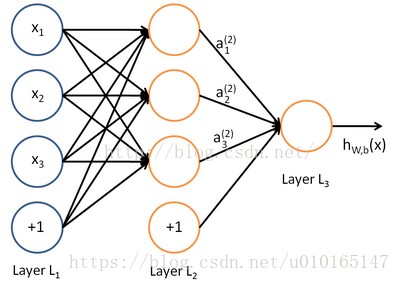
上面是一个简单多层感知机神经网络(MLP)结构,公式为(这里假设激活函数为 R e L U ReLU ReLU, R e L U ( x ) = m a x ( x , 0 ) ReLU(x)=max(x,0) ReLU(x)=max(x,0)):
a i ( 2 ) = R e L U ( ∑ k = 1 3 w i k ( 1 ) ∗ x k + b ( 1 ) ) a_i^{(2)}=ReLU(\sum_{k=1}^3 w_{ik}^{(1)}*x_k+b^{(1)}) ai(2)=ReLU(∑k=13wik(1)∗xk+b(1))
h w , b ( x ) = R e L U ( ∑ i = 1 3 w i ( 2 ) ∗ a i ( 2 ) + b ( 2 ) ) h_{w,b}(x)=ReLU(\sum_{i=1}^3w_i^{(2)}*a_i^{(2)}+b^{(2)}) hw,b(x)=ReLU(∑i=13wi(2)∗ai(2)+b(2))
这里我们不去深究以上具体的公式内容,对于每一层(除输入层)都可以用如下简单的数学公式表示:
f ( x ) = R e L U ( ∑ i = 1 n w i ∗ x i + b ) f(x)=ReLU(\sum_{i=1}^n w_{i}*x_i+b) f(x)=ReLU(∑i=1nwi∗xi+b)
以上公式我们可以转换为矩阵形式,即:
f ( X ) = R e L U ( W T X + b ) f(X)=ReLU(W^TX+b) f(X)=ReLU(WTX+b)
这里我们假设 ∣ ∣ W ∣ ∣ = ∣ ∣ X ∣ ∣ = 1 ||W||=||X||=1 ∣∣W∣∣=∣∣X∣∣=1 即 W W W 和 X X X 的范数都为 1 1 1,这时 W W W 和 X X X都为归一化向量,可以得到
W T X = W T X ∣ ∣ W ∣ ∣ ∗ ∣ ∣ X ∣ ∣ = c o s ( θ ) W^TX=\frac{W^TX}{||W||*||X||}=cos(\theta) WTX=∣∣W∣∣∗∣∣X∣∣WTX=cos(θ),其中 c o s ( θ ) ∈ [ − 1 , 1 ] cos(\theta)\in[-1,1] cos(θ)∈[−1,1]
所以神奇的事情发生了,矩阵乘法等价于cosine相似度。区别只在向量的长度,cosine相似度是归一化后的,而原始 W T X W^TX WTX是非归一化的。在实践中因为神经网络的梯度爆炸和消失问题,我们往往会使用BatchNorm即批规范化,使每层的输入的分布都归一化到[-1,1]之间,当我们可视化其中权重的时候会发现权重绝大多数都介于[-1,1]之间,也就是即便权重 W W W不是归一化的,其向量长度仍然很小。很多论文已经表明使用归一化的权重和未归一化权重并没有显着差别[2-3]。
所以我们完全可以使用cosine相似度替代 W T X W^TX WTX,即(这里的 ∣ ∣ W ∣ ∣ ||W|| ∣∣W∣∣和 ∣ ∣ X ∣ ∣ ||X|| ∣∣X∣∣不再等于 1 1 1):
f ( X ) = R e L U ( W T X ∣ ∣ W ∣ ∣ ∗ ∣ ∣ X ∣ ∣ + b ) = R e L U ( c o s ( θ ) + b ) f(X)=ReLU(\frac{W^TX}{||W||*||X||}+b)=ReLU(cos(\theta)+b) f(X)=ReLU(∣∣W∣∣∗∣∣X∣∣WTX+b)=ReLU(cos(θ)+b)
我们看到激活函数的作用是什么?对不相似的输入不响应,即相似度大于 − b -b −b才有输出。所以我们看到 M L P MLP MLP本质在比较输入 X X X 和 W W W 的相似度,如果相似度大于 − b -b −b才有输出,否则不输出(和SVM超平面类似,这里也相当于构造了一个分割超平面,只是深层神经网络分割次数非常多,层次越深分割次数越多); 这里 W W W 即论文中经常提到的anchor(锚定矩阵),有的时候我喜欢把它叫观测矩阵,或者叫尺子,即我们能用它来测量输入与自身的差异,或者更哲学的我们能看到什么取决于我们有什么
同样,在计算机视觉中广泛使用的卷积神经网络( C N N CNN CNN)和多层感知机神经网络并无本质的区别,形式都是 f ( X ) = R e L U ( W T X ) f(X)=ReLU(W^TX) f(X)=ReLU(WTX),区别仅仅在于 C N N CNN CNN中矩阵乘法是局部(或分patch)的,而权重参数在多个局部都是可重用的,因此权重参数比同等条件下的 M L P MLP MLP少得多。
有人会说我用 s i g m o i d sigmoid sigmoid和 t a n h tanh tanh激活函数呢?[6]这篇文章说明了 s i g m o i d sigmoid sigmoid和 t a n h tanh tanh是同胚映射(homeomorphism),同胚映射是保拓扑结构的,如下图,同胚映射无法完全区分两个连接的轮胎拓扑,而ReLU不是同胚映射,ReLU 可以直接对轮胎拓扑作切割,对于不相似的区域直接切掉或者过滤掉,这是为什么用ReLU的原因之一,当然 s i g m o i d sigmoid sigmoid和 t a n h tanh tanh也有梯度爆炸和消失问题,和这里讨论的问题有些区别

使用cosine相似度替代 W T X W^TX WTX也有他的缺陷, W T X = ∣ ∣ W ∣ ∣ ∗ ∣ ∣ X ∣ ∣ ∗ c o s ( θ ) = ∣ ∣ V ∣ ∣ ∗ c o s ( θ ) W^TX=||W||*||X||*cos(\theta)=||V||*cos(\theta) WTX=∣∣W∣∣∗∣∣X∣∣∗cos(θ)=∣∣V∣∣∗cos(θ)我们发现当两个数据与 W W W 的夹角 θ \theta θ 相同时使用cosine相似度这两个数据将无法区分,但是 W T X = ∣ ∣ V ∣ ∣ ∗ c o s ( θ ) W^TX=||V||*cos(\theta) WTX=∣∣V∣∣∗cos(θ) 可以使用 ∣ ∣ V ∣ ∣ ||V|| ∣∣V∣∣ 即:向量长度区分,如 ∣ ∣ V ∣ ∣ ||V|| ∣∣V∣∣ 为 1 和 5 是可以被区分的,所以相对的 W T X W^TX WTX 比 c o s ( θ ) cos(\theta) cos(θ) 有更大的模式容量
参考文献 Understanding Convolutional Neural Networks with A Mathematical ModelCosine Normalization: Using Cosine Similarity Instead of Dot Product in Neural NetworksSphereFace: Deep Hypersphere Embedding for Face RecognitionDeep Hyperspherical LearningArcFace: Additive Angular Margin Loss for Deep Face RecognitionNeural Networks, Manifolds, and Topology网址:神经网络与Cosine相似度 https://www.yuejiaxmz.com/news/view/505945
相关内容
深度神经网络训练的必知技巧【机器学习】深度神经网络(DNN):原理、应用与代码实践
详解神经网络各层的结构与功能
神经网络调参总结
卷积神经网络
AI = 神经网络?这8个技术就不是!
神经网络与智能家居:未来的智能生活
Tensorflow笔记之【神经网络的优化】
Matlab代码实践——BP神经网络
【转载】关于训练神经网路的诸多技巧Tricks(完全总结版)
随便看看
最新动态分享
- 家庭消毒不用愁!5大物理消毒法守护健康生活
- カビをアルコール退治|消毒用エタノールでの除菌方法やNG使用法も
- 消毒产品目录
- 基于STM32的智能鞋柜控制系统设计与实现
- 【解決】家具に生えたカビの取り方、予防法、原因を紹介
- 抗菌实验不同操作方法及细节对试验结果的影响
- 多部门推动物联网创新发展 到2028年这些技术要突破
- 生活区节水节电节能管控措施.docx
- 家庭节约用电有哪些具体方法?
- 北京市出台碳普惠管理办法 市民低碳行为将能“变现”
热点动态分享
- 145119
- 52542
- 45142
- 42504
- 40948
- 30924
- 25727
- 25539
- 21933
- 18656

