
 maoreyou 于 2018-05-30 16:11:15 发布
maoreyou 于 2018-05-30 16:11:15 发布摘要: 随着云计算和IoT的发展,时间序列数据的数据量急剧膨胀,高效的分析时间序列数据,使之产生业务价值成为一个热门话题。阿里巴巴数据库事业部的HiTSDB团队为您分享时间序列数据的计算分析的一般方法以及优化手段。
演讲嘉宾简介:钟宇(悠你) 阿里巴巴 数据库高级专家,时间序列数据库HiTSDB的研发负责人。在数据库、操作系统、函数式编程等方面有丰富的经验。
本次直播视频PPT,戳这里!
本次分享主要分为以下几个方面:
1. 时序数据库的应用场景
2. 面向分析的时序数据存储
3. 时序数据库的时序计算
4. 时序数据库的计算引擎
5. 时序数据库展望
一,时序数据库的应用场景
时序数据就是在时间上分布的一系列数值。生活中常见的时序数据包括,股票价格、广告数据、气温变化、网站的PV/UV、个人健康数据、工业传感器数据、服务器系统监控数据(比如CPU和内存占用率)、车联网等。
下面介绍IoT领域中的时间序列数据案例。IoT给时序数据处理带来了很大的挑战。这是由于IoT领域带来了海量的时间序列数据:
1. 成千上万的设备
2. 数以百万计的传感器
3. 每秒产生百万条数据
4. 24×7全年无休(区别于电商数据,电商数据存在高峰和低谷,因此可以利用低谷的时间段进行数据库维护,数据备份等工作)
5. 多维度查询/聚合
6. 最新数据实时可查
IoT中的时间序列数据处理主要包括以下四步:
1. 采样
2. 传输
3. 存储
4. 分析
二,面向分析的时序数据存储
下面介绍时间序列数据的一个例子。这是一个新能源风力发电机的例子。每个风力发电机上有两个传感器,一个是功率,一个是风速,并定时进行采样。三个设备,一共会产生六个时间序列。每个发电机都有多种标签,这就会产生多个数据维度。比如,基于生产厂商这个维度,对功率做聚合。或基于风场,对风速做聚合等。现在的时序数据库底层存储一般用的是单值模型。因为多值模型也可以一对一的映射到单值模型,但这个过程可能会导致性能损失。但是,在对外提供服务时,单值模型和多值模型都有应用。比如,OpenTSDB就是用单值模型对外提供服务的,而influxDB则是多值模型。但这两种数据库的底层存储用的都是单值模型。
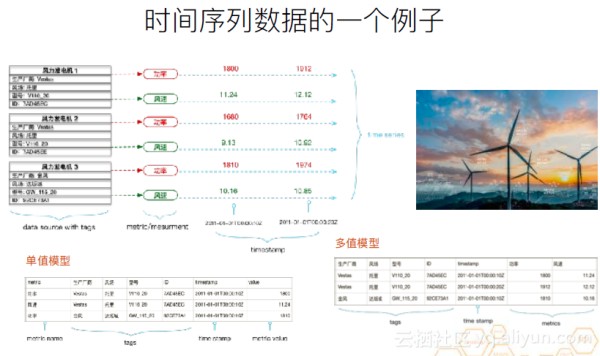
现实中的应用案例事实上会更复杂。像风力发电机这样的案例,它的设备和传感器的数量,我们可以认为是稳中有增的,不会发生特别剧烈的改变。它的数据采样的周期也是严格的定期采样。下图是一个工业案例,以滴滴这样

