[动态规划]4 状态压缩(空间优化)
定期检查空调压缩机运行状态 #生活技巧# #汽车保养技巧# #汽车空调保养#
参考:
对动态规划发动降维打击动态规划的优化动态规划之空间优化与总结回顾动态规划本身也是可以进行阶段性优化的,比如说我们常听说的「状态压缩」技巧,就能够把很多动态规划解法的空间复杂度进一步降低,由 O(N^2) 降低到 O(N)。
能够使用状态压缩技巧的动态规划都是二维 dp 问题。
你看它的状态转移方程,如果计算状态 dp[i][j] 需要的都是 dp[i][j] 相邻的状态,那么就可以使用状态压缩技巧,将二维的 dp 数组转化成一维,将空间复杂度从 O(N^2) 降低到 O(N)。
状态压缩的目的就是“空间优化”。
什么是“相邻状态”?
那什么叫「和 dp[i][j] 相邻的状态」呢,比如前文 最长回文子序列 中,最终的代码如下:
int longestPalindromeSubseq(string s) { int n = s.size(); // dp 数组全部初始化为 0 vector<vector<int>> dp(n, vector<int>(n, 0)); // base case for (int i = 0; i < n; i++) dp[i][i] = 1; // 反着遍历保证正确的状态转移 for (int i = n - 2; i >= 0; i--) { for (int j = i + 1; j < n; j++) { // 状态转移方程 if (s[i] == s[j]) dp[i][j] = dp[i + 1][j - 1] + 2; else dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); } } // 整个 s 的最长回文子串长度 return dp[0][n - 1]; }
c++
运行
从代码中可以看出,我们对dp[i][j]的更新只依赖于dp[i+1][j-1], dp[i][j-1], dp[i+1][j]这三个状态:
(图1)
这就叫和 dp[i][j] 相邻,反正你计算 dp[i][j] 只需要这三个相邻状态,其实根本不需要那么大一个二维的 dp table 对不对?状态压缩的核心思路就是,将二维数组「投影」到一维数组:
(图2)
一维的的状态压缩
一维的状态压缩,其实就是将一维 DP table 压缩到 使用常数个变量来保存有用的数据。
如我们之前的斐波那契数列 代码如下:
//法3:dp 数组的迭代解法(Bottom-up) class Solution { public: int fib(int n) { if (n < 1) return 0; std::vector<int> dp(n, 0); // base case dp[0] = dp[1] = 1; for(int i =2; i <= n; i++) { dp[i] = dp[i - 1] + dp[i - 2]; } return dp[n-1]; } };
c++
运行
首先,根据状态转移方程:dp[i] = dp[i - 1] + dp[i - 2],同时我们将dp数组的前几项写出来便于观察规律:
11235813213455dp[0]dp[1]dp[2]dp[3]dp[4]dp[5]dp[6]dp[7]dp[7]dp[8]从上面我们可以观察到,我们每次只需要知道dp[i - 1] 、 dp[i - 2]的值就可以求出dp[i]的值。而当我们求出dp[i]之后,当前的dp[i-2]就不再需要了。所以,我们其实就可以只用两个变量来保存,然后每次都进行滚动更新(这也叫==滚动数组==):
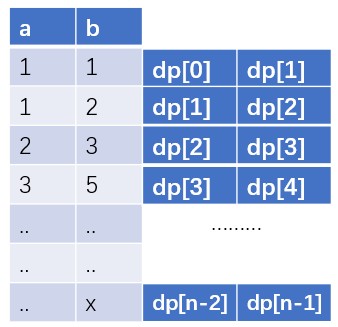
如上图所示,我们只使用了两个变量a、b就可以完成一维dp table 所完成的工作。我们每次更新a,b的值。然后就可以将一维的dp数组压缩成长度为2的数组,从而达到状态压缩,即空间优化的效果。
对应的空间优化的代码如下:
//法3:dp 数组的迭代解法(Bottom-up) class Solution { public: int fib(int n) { if (n < 1) return 0; //b std::vector<int> dp(n, 0); int a = 1, b = 1; // 只需要2个(也是base case) // base case // dp[0] = dp[1] = 1; for(int i =2; i <= n; i++) { // dp[i] = dp[i - 1] + dp[i - 2]; int temp = b; // 待会需要将该值更新给a b = a + b; a = temp; } return b; } };
c++
运行
所以,我们把空间复杂度由O(N)压缩为O(1)。
二维的状态压缩
情况1:当前值 只与 前面2个值有关
我们看LeetCode的一个题目62. 不同路径:
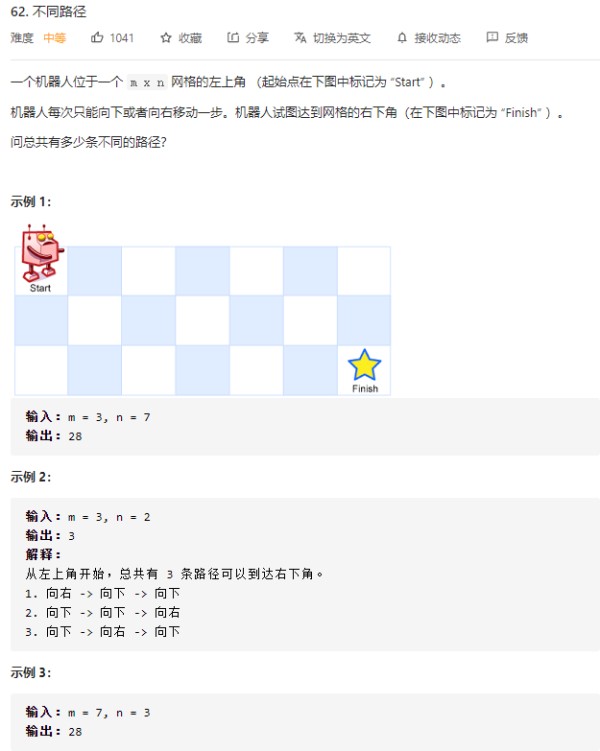
由题目我们可以分析出,其dp状态转移公式为:dp[i] [j] = dp[i-1] [j] + dp[i] [j-1]。
我们先写出空间优化之前的代码:
class Solution { public:int uniquePaths(int m, int n) {// 备忘录:当走到(i,j)处时,路径的可能性有多少vector<vector<int>> dp(m, vector<int>(n, -1));// base casefor (int i = 0; i < n; i++) // 第一行的dp值dp[0][i] = 1;for (int j = 0; j < m; j++) // 第一列的dp值dp[j][0] = 1;// 状态转移for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {dp[i][j] = dp[i][j - 1] + dp[i - 1][j];}}return dp[m-1][n-1];} };
c++
运行
这种做法的空间复杂度是 O(n * m),下面我们来讲解如何优化成 O(n)。
二维dp数组注意:我们的行数是从0开始的。
下面我们将这二维的DP数组用图的方式展示:
(初始情况,第0行的值为1)
我们知道初始情况为:第0行的值都为1。下面我们来根据公式 dp[i][j] = dp[i-1][j] + dp[i][j-1]来填充矩阵的其他值。下面我们先填充第二行的值。
(填充第1行)
此时,我们发现要填充第2行的值的时候,已经不需要第0行的值了。而且,再结合dp公式可知:当我们要计算第 i 行的值时,除了会用到第 i - 1 行外,其他第 1 至 第 i-2 行的值我们都是不需要用到的。那既然不需要了,我们就没必要保存它们了。
方法1 :压缩为1维数组我们只需要用一个一维的 dp[] 来保存一行的历史记录就可以了。然后在计算机的过程中,不断着更新 dp[] 的值。
接下来,我们就演示一下。
1、刚开始初始化第一行,此时 dp[0 … n-1] 的值就是第一行的值。
2、接着我们来一边填充第二行的值一边更新 dp[i] 的值,一边把第一行的值抛弃掉。
显然,矩阵(1, 0) 的值相当于以往的初始化值,为 1。然后这个时候矩阵 (0,0)的值不在需要保存了,因为再也用不到了。
跟着更新 dp[0] 的值了,刚开始 dp[0] 的值是矩阵 (0, 0),现在更新dp[0] 为 (1, 0)处的值。
接着继续更新 (1, 1) 的值,根据之前的公式 (i, j) = (i-1, j) + (i, j- 1)。即 (1,1)=(0,1)+(1,0)=2。
以往的二维的时候, dp[i][j] = dp[i-1] [j]+ dp[i][j-1]。现在转化成一维,不就是 dp[i] = dp[i] + dp[i-1] 吗?
即 dp[1] = dp[1] + dp[0],而且还动态帮我们更新了 dp[1] 的值。因为刚开始 dp[i] 的保存第一行的值的,现在更新为保存第二行的值。即,执行完 dp[1] = dp[1] + dp[0]后,就自动更新了dp[1]:
同样的道理,按照这样的模式一直来计算第1行的值,顺便把第0行的值抛弃掉,结果如下:
此时,dp[i] 将完全保存着第1行的值,并且我们可以推导出公式:dp[i] = dp[i-1] + dp[i]。
dp[i-1]相当于之前的dp[i-1][j],dp[i] 相当于之前的dp[i][j-1]。
3、于是按照这个公式不停着填充到最后一行,结果如下:
最后dp[n-1]就是我们要求的结果了。
所以优化之后,代码如下:
// 法2: 空间优化 class Solution { public:int uniquePaths(int m, int n) {// 备忘录:当走到(i,j)处时,路径的可能性有多少// vector<vector<int>> dp(m, vector<int>(n, -1));vector<int> dp(n, 1); // 一维、base case// 状态转移for (int i = 1; i < m; i++) {dp[0] = 1; // 第i行的第0列 的初始值for (int j = 1; j < n; j++) {//dp[i][j] = dp[i][j - 1] + dp[i - 1][j];dp[j] = dp[j] + dp[j - 1];}}return dp[n-1];} };
c++
运行
方法2:滚动数组实质上,滚动数组的原理就是保存哪些我们有用的数据所在的行。如我们这一题需要的数据在第i行,和第i-1行,那我就把这两行的数据全都保存。
这是和 压缩为1维数组不一样的地方。
接下来,我们看看具体代码如何实现:
class Solution { public:int uniquePaths(int m, int n) {// dp,注意我们这里只保存两行的数据vector<vector<int>> dp(2, vector<int>(n, -1));// base casefor (int i = 0; i < n; i++) // 第0行的dp值dp[0][i] = 1;for (int j = 0; j < 2; j++) // 第0列的dp值dp[j][0] = 1;// 状态转移for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {dp[i % 2][j] = dp[i % 2][j - 1] + dp[(i - 1) % 2][j];}}return dp[(m-1) % 2][n - 1];} };
c++
运行
可以看到,我们利用取余来将这些数据保存在两行中。
情况2: 当前值 与前面3个值有关
接着我们来看另外一道题,就是**72. 编辑距离**,这道题的优化和这一道有一点点的不同,上面这道 dp[i][j]依赖于 dp[i-1][j] 和 dp[i][j-1]。
而编辑距离就是dp[i][j] 依赖于 dp[i-1][j],dp[i-1][j-1] 和dp[i][j-1]。

先给出空间优化之前的代码:
// 2. 动态规划 (dp table) class Solution { public:int minDistance(string word1, string word2) { int m = word1.size(); int n = word2.size(); // dp table vector<vector<int> > dp(m+1, vector<int>(n+1, -1)); // base case for(int i = 0; i <= m; i++) dp[i][0] = i; for(int j = 0; j <= n; j++) dp[0][j] = j; // 自底向上求解 for(int i = 1; i <= m; i++) { for(int j = 1; j <= n; j++) { if(word1[i-1] == word2[j-1]) dp[i][j] = dp[i-1][j-1]; else { int a = dp[i][j-1] + 1; // 插入 int b = dp[i-1][j] + 1; // 删除 int c = dp[i-1][j-1] + 1; // 替换 dp[i][j] = min(a, min(b, c)); } } } return dp[m][n];} };
c++
运行
没有优化之间的空间复杂度为 O(n*m)。
二维dp数组下面我们依然是先展示一下该例题的二维dp数组: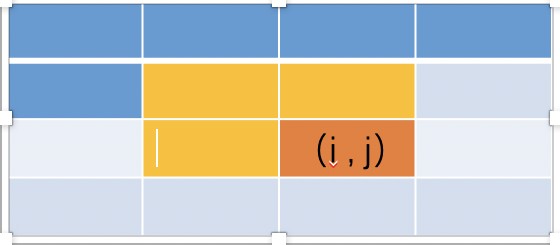
我们可以看出,如果要计算 第 i 行的值,我们最多只依赖第 i-1 行的值,不需要用到第 i-2 行及其以前的值,所以一样可以采用一维 dp 来处理的。
不过这个时候要注意,在上一个例子中,我们每次更新完 (i, j) 的值之后,就会把 (i, j-1) 的值抛弃,也就是说之前是一边更新 dp[i] 的值,一边把 dp[i] 的旧值抛弃的,不过在这道题中则不可以,因为我们还需要用到它。
所以,对于这种情况,我们还需要一个额外的变量pre 来时刻保存 (i-1,j-1) 的值。
// 推导公式就可以从二维的: dp[i][j] = min(dp[i-1][j] , dp[i-1][j-1] , dp[i][j-1]) + 1 // 转化为一维的 dp[i] = min(dp[i-1], pre, dp[i]) + 1。
text
所以呢,案例2 其实和案例1 差别不大,就是多了个变量来临时保存。最终代码如下:
方法1: 压缩为1维数组// 2. 动态规划 (dp table) class Solution { public: int minDistance(string word1, string word2) { int m = word1.size(); int n = word2.size(); if (m == 0 && n == 0) return 0; // dp table vector<int> dp(n + 1, -1); // base case for (int j = 0; j <= n; j++) { dp[j] = j; } // 自底向上求解 for (int i = 1; i <= m; i++) { int temp = dp[0]; // 每次计算下一行时,开始先保存上一行计算的dp[0]⭐ dp[0] = i; // 更新dp[0]⭐ for (int j = 1; j <= n; j++) { int pre = temp; // ⭐ temp = dp[j]; // ⭐ if (word1[i - 1] == word2[j - 1]) //dp[i][j] = dp[i - 1][j - 1]; dp[j] = pre; else { int a = dp[j - 1] + 1; // 插入 int b = dp[j] + 1; // 删除 //int c = dp[i - 1][j - 1] + 1; // 替换 dp[j] = min(a, min(b, pre+1)); } } } return dp[n]; } };
c++
运行
对于上面的pre、temp变量出现的位置,及更新时机进行解释:
首先,我们给出一个例子:
int temp = dp[0];是在每一次遍历下一行时,第一个执行的语句。它表示将上一次遍历的1维dp数组结果中的dp[0]赋值给temp,用图表示:
即,比如我们此时i=2,执行int temp = dp[0];就表示把外部循环上一次遍历的结果(存在1位dp数组中)中的dp[0]赋值给temp。
dp[0] = i; 此时我们已经在计算第2行的值了。所以,我们要更新dp数组的值,此时dp[0]=i就是在更新,即第2行的dp[0] = 2。
int pre = temp; 这是在内层循环中,pre就表示我们之前所说的dp[i-1][j-1]的值。
temp = dp[j]; 内部循环中。它的作用是临时保存上一次(比如我们现在i=2时,那我们就是在保存上一层的第j列的值。对应在二维中就是保存的是dp[i-1][j])。以便下一次(j++)的循环时,是的pre能够更新。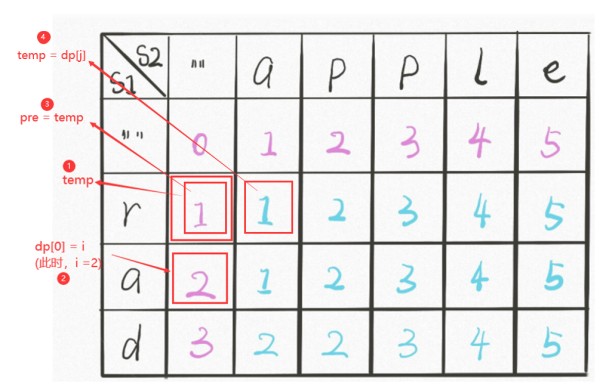
我们也是这使用滚动数组,来进行代码的书写:
// 2. 动态规划 (dp table) class Solution { public:int minDistance(string word1, string word2) {int m = word1.size();int n = word2.size();// dp tablevector<vector<int> > dp(2, vector<int>(n + 1, -1));// base casefor (int j = 0; j <= n; j++)dp[0][j] = j;// 自底向上求解for (int i = 1; i <= m; i++){dp[i%2][0] = i; // 修改来源于:https://leetcode-cn.com/problems/edit-distance/solution/javajie-fa-er-wei-dong-tai-gui-hua-gun-d-l8ng/for (int j = 1; j <= n; j++){if (word1[i - 1] == word2[j - 1])dp[i%2][j] = dp[(i - 1)%2][j - 1];else {int a = dp[i%2][j - 1] + 1; // 插入int b = dp[(i - 1)%2][j] + 1; // 删除int c = dp[(i - 1)%2][j - 1] + 1; // 替换dp[i%2][j] = min(a, min(b, c));}}}return dp[m%2][n];} };
c++
运行
小结
将二维dp数组压缩为1维的,要空间优化的程度要好于 滚动数组的。
但是,二维dp数组压缩为1维 比较难于实现。难点在于额外变量pre的更新时机。而滚动数组相对来说就比较容易实现。
网址:[动态规划]4 状态压缩(空间优化) https://www.yuejiaxmz.com/news/view/1099821
相关内容
动态规划的空间压缩技巧(降低空间复杂度)动态规划的时间复杂度优化
动态规划:空间优化技巧以及接龙型动态规划
二维动态规划空间优化
动态规划优化技巧.doc
动态规划之空间优化与总结回顾
动态规划的优化与高级应用
动态规划算法的优化技巧(转贴)
动态规划 多重01背包及空间开销优化
简阳市强化国土空间规划引领,优化“生产、生活、生态”空间格局
随便看看
最新动态分享
- 20条必看行车安全知识:老司机也可能忽略的细节
- 行车安全的小常识?
- 安全文明驾驶小知识
- 冬季安全行车小常识
- 涞源公安交警大队制作道路交通安全常识小漫画,请查收~
- 日常生活安全知识:遇到危险要怎么逃生?(参考版)
- 小学生安全知识讲座[推荐阅读]
- 寒假中学生居家安全小常识
- “是非成败转头空,青山依旧在,几度夕阳红。”全诗赏析
- “休言万事转头空,未转头时皆梦。”全诗赏析
热点动态分享
- 144114
- 45480
- 44256
- 39887
- 38059
- 29600
- 24628
- 24345
- 20875
- 17860

