AI智能体落地:Agent
AI在游戏设计中提升智能化体验 #生活知识# #科技生活# #人工智能应用#
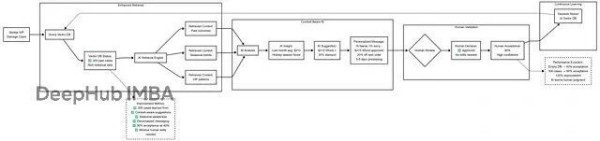
今年开始LLM驱动的Agentic AI发展速度非常惊人。而我们现在面临一个实际问题:到底是上全自主的AI智能体,还是让人类继续参与决策?从大量实际案例来看Agent-Assist(也就是Human-in-the-Loop系统)既能带来自动化的效率提升,又能有效规避那些可能造成重大损失的错误。
而且如果系统设计得当的话,还可以从人类每次纠正中学习,持续积累组织自己的专业知识库。
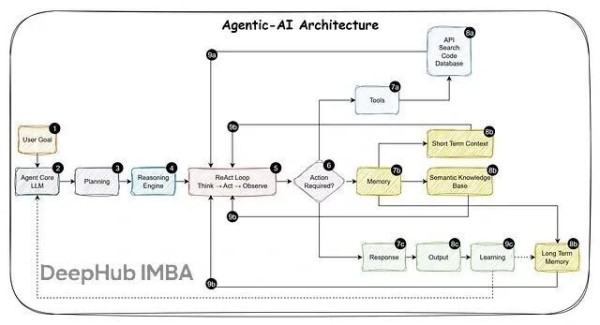
概念回顾
Human-in-the-Loop (HITL):这个概念范围比较广,一般指的是人类参与AI决策流程,负责审查、纠正或引导AI的输出。在机器学习训练、内容审核、模型优化这些场景里很常见。
Agent-Assist:这是HITL的一种具体应用形式,专注于实时操作支持。AI负责起草邮件、总结通话内容、提供背景信息或者写代码,但最终决策和执行还是由人来完成。
Agent-Assist是HITL原则在实际业务场景中的落地:
两者核心思路一致——人类保留决策权而AI充当辅助角色。这两个的主要区别在于,Agent-Assist更强调实时的生产力提升(帮知识工作者提高效率),而HITL是个更宏观的框架,还包含了训练、质控、系统改进等流程。所以一般讨论Agent-Assist时,通常说的就是那些专门为提升知识工作者生产力而优化的HITL系统。
2025年Agentic AI大爆发
ChatGPT刚出来的时候,大家觉得它能写邮件、解释概念已经很厉害了。而现在的AI智能体能做的事情完全不是一个量级:
Lindy和Operator可以自动帮你约会议,读你的日历和邮件就行;Cursor、Claude Code、Devin、GitHub Copilot Workspace这些工具能自主写代码并部署;Sierra和Ada CX可以端到端处理客户支持;Bloomberg GPT智能体在执行复杂金融交易;Honeycomb的AI操作员在大规模管理云基础设施。
Agentic AI系统能独立规划任务、执行多步骤操作、调用各种工具,并根据结果动态调整策略,远不止聊天机器人那么简单。核心能力包括:LLM推理、工具使用(API、数据库、代码执行)、记忆系统、决策循环。
所以问题就来了这些智能体该完全自主运行,还是应该保持人类在关键决策环节?
两种方案的实际对比
场景:客户退款请求
方案1:完全自动化
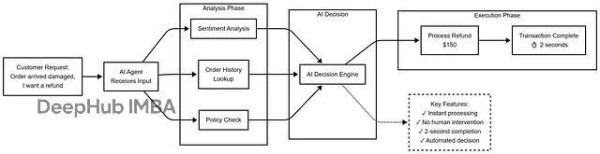
方案2:Agent-Assist (Human-in-the-Loop)

对比结果:
自主版本处理快,但错失了维护VIP客户的战略机会。Agent-Assist版本虽然慢一点点,但AI这次学到了要区别对待VIP客户下回会建议更合适的方案。
核心优势:持续学习能力
Agent-Assist能创建一个持续学习循环,而且不需要昂贵的模型重训。
RAG(Retrieval-Augmented Generation)
不用微调或重训LLM,直接用RAG配合向量数据库来建立组织记忆。
每个人类决策都存进向量数据库(Pinecone、Weaviate、Qdrant、PgVector、Milvus等等),记录包括:上下文(客户类型、具体情况)、AI原始建议、人类最终决策、修改理由、执行结果。
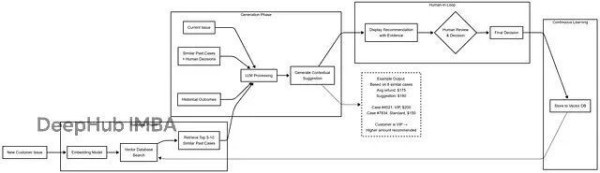
学习曲线(假设场景)
第1个月:AI建议,人类批准或编辑60%的内容。系统开始收集真实决策数据,学到"客户说X时,人类倾向选择Y"、"VIP客户待遇不同"、"时机有讲究(比如假期会更慷慨)"。
第6个月:接受率升至80%。向量库已经有几千条人类决策记录了。每个新案例AI会检索5-10个最相似的历史决策。AI看到"8/10的类似案例里,人类都选了Z方案",然后根据这些组织知识调整建议。人类编辑的时间少多了,因为AI有了上下文记忆。
第12个月:接受率达到90%。向量库存了3万多条决策,这就是全面的组织记忆了。AI同时检索短期模式和长期经验,初级员工通过RAG能获取到资深专家的决策智慧。系统改进靠的是知识库扩充,不是模型重训。
实际效果对比
第1周:空白状态
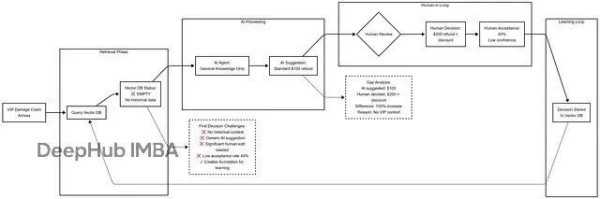
第12周:丰富记忆
这些进步来自向量数据库的扩充,跟重训LLM没关系。
RAG为什么比微调更适合Agent-Assist
不需要搞复杂的重训流程,往向量库加数据就行;新决策实时可用,立即生效;完全透明能看到哪些历史案例影响了当前建议;随时编辑、删除坏例子或更新策略都很方便;成本低不用GPU集群也不用重训算力;可解释性强能说清"基于这5个类似案例...";多模态记忆,决策、结果、上下文、用户反馈都存;还能做版本控制,跟踪组织知识怎么演化的。
而工程复杂(训练管道、GPU基础设施)、费用高、迭代慢(更新要好几天甚至几周)、有灾难性遗忘风险(新训练覆盖旧知识)、黑盒操作(不知道具体改了啥)、需要ML/DL专业技能。
系统如何从人类反馈中学习
人类每次跟AI建议互动,系统都会捕获这个决策存档。不同类型的反馈教会AI不同的东西:
1、直接批准:"这次对了"
人类不做任何修改就批准AI建议时,系统记为成功模式。
比如AI建议对损坏商品退款150美元,人类点了批准,系统就知道这个因素组合(损坏类型、客户等级、订单金额)适合150美元退款。
学到的经验:"这个模式有效,类似情况继续用"。
2、编辑修改:"方向对了,但具体操作要这样"(价值最高)
人类修改AI建议时,其实是在传授任何训练数据里都没有的公司特定知识。
例子:
AI建议:"尊敬的客户,您的退款已处理。"
人类改成:"嗨Victor,很抱歉你收到的订单有损坏。我已经处理了200美元退款,另外给你下次购买提供20%折扣。退款会在3-5个工作日到账,感谢你的耐心。"
AI学到:VIP客户要称呼名字、表达真诚歉意、说明时间线、附加补偿措施。下次类似情况AI会自动建议这种个性化处理。
这是最有价值的信号,因为它捕获了没法手动编程的专家经验。
3、完全拒绝:"这不是正确处理方式"
人类拒绝AI建议并选择完全不同的方案时,说明AI对情况的理解根本就错了。比如AI按标准政策建议退50美元,人类拒绝后批准200美元加折扣码,因为识别出这是个有流失风险的高价值VIP客户。
AI学到:"这类客户档案 + 这类情况 = 需要高级处理,不能套标准政策"。以后遇到VIP损坏问题,初始建议额度就会更高。
4、结果追踪:"决策效果如何"
系统能跟踪决策后续,客户满意吗?有没有复购?问题解决了吗?
例如那个200美元退款决策,两周后的数据 客户满意度9.5/10、续订了年度订阅、又买了2000美元的东西、状态:成功保留。
AI学到:"对VIP客户的慷慨策略能创造长期价值,继续推荐这个方向"。时间长了,AI会建立起基于实际结果的理解,知道哪些方法真正有效,而不只是看起来不错。
什么情况适合完全自动化
说了很多不适合自动化的场景,我们再说说有些场景确实适合完全自主。
高频低风险操作
垃圾邮件过滤(Gmail每天处理数十亿封,出错可以容忍)、内容推荐(Netflix、Spotify)、广告竞价(毫秒级决策、易回退)、日志聚合和基础监控。
边界清晰的窄领域
云基础设施自动扩容(规则明确、可逆)、基础客服FAQ(事实性问答、低风险)、数据验证格式化、常规代码检查和格式化。
速度是硬性要求
欺诈检测(毫秒内必须拦截)、DDoS防御(等不了人工批准)、高频交易(虽然要有严格护栏)。
决策框架
什么时候该用Agent-Assist?
满足以下任一条件就该用:错误成本超过1000美元(看具体组织风险承受度)、影响客户资金/隐私/安全、有行业监管要求(金融/医疗/法律)、涉及模糊性或强上下文依赖、需要持续学习改进、经常遇到新情况、人类有值得保留的专业经验、错误难以回退。
什么时候考虑完全自动化?
必须同时满足所有条件:高频(每小时1000+决策)、低风险(单次错误成本<100美元)、易回退、规则明确、无人工审核的监管要求、完成充分测试(影子模式>90天)、监控告警到位、验证过回滚机制。
建议:就算完全自动化看起来没问题,也最好先从Agent-Assist开始,收集训练数据并建立信心。
总结
LLM和Agentic AI能力在爆炸式增长,完全自动化的诱惑确实很大。但真正能赢的公司,是那些懂得增强人类智能而非取代人类的公司,构建的系统能从团队每天的决策中不断变聪明。
Agent-Assist不是要减慢创新速度,恰恰相反它是为了构建这样的AI系统:学习组织的独特专业知识、在错误造成损失前就拦截、自然符合监管要求、无需昂贵培训就能持续改进、让核心人才专注高价值工作。
聪明的自动化策略是让AI处理速度和规模,人类贡献判断和适应能力。工作的未来不是人类对抗AI,而是人类与AI协作。
作者:Rajesh Srivastava
点个 在看 你最好看!
免责声明:本内容来自腾讯平台创作者,不代表腾讯新闻或腾讯网的观点和立场。
 举报
举报
网址:AI智能体落地:Agent https://www.yuejiaxmz.com/news/view/1405938
相关内容
AI Agent商用落地:提升设备智能,助力生活与工作AI Agent(智能体)专题报告:从技术概念到场景落地指南
2025企业级AI Agent(智能体)价值及应用报告
AI Agent如何重塑未来智能家居的体验
智能体走进家居生活,COLMO AI Agent破壁前行
AI科普:探索人工智能体(Agent)的世界
AI 智能体(AI Agent)的应用场景
写给小白的大模型应用指南:AI Agent 智能体篇
智能家居AI Agent:控制定制一体化的未来生活新体验
智能家居AI Agent控制定制实现:打造个性化智能生活新体验
随便看看
最新动态分享
- 适合搭配的食材
- 食疗养生大全:67种天然食材搭配与食疗方,吃出健康好气色
- 哪些食材可以搭配食用 十对最佳食材搭配好吃又健康
- 壮阳补肾煲汤大全:中药配方与食材搭配全解析
- 广东鱼肚汤的家常做法大全|营养功效+食材搭配+5种经典汤谱(附详细步骤)
- 四季美容养颜豆浆配方大全|天然食材搭配+科学原理,喝出透亮肌
- 零失败家常小炒菜谱大全(附新手必学技巧+食材搭配指南)
- 补肾食谱大全:10种家常食疗方+食材清单,科学搭配提升肾动力
- 5种营养搭配!家常鸡汤快手做法大全(附不同做法+食材禁忌)
- 麻辣香锅食材菜单大全图
热点动态分享
- 144569
- 47425
- 44598
- 40333
- 39880
- 30565
- 25104
- 24907
- 21496
- 18260

