八爪鱼网络爬虫工具——学习笔记整理
利用网络工具同步备份纸质和电子笔记 #生活技巧# #学习技巧# #笔记技巧#
八爪鱼是一款网页爬虫工具,可以不用编写代码快速实现网页数据的爬取。
关于其基础操作,可以在其官网的使用教程http://www.bazhuayu.com/tutorialIndex 进行查看。其中主要针对其翻页和带有验证码的登录以及xpath操作进行阐述。
特殊翻页
数字翻页
在制作采集规则时,页面没有“下一页”等翻页按钮,而是一排页码,如"1","2","3","4","5"……
如何通过数字翻页的进行处理?
解决思路:
找到一条xpath,使得在当前页(除未页外)始终能定位到下一页。
示例网址:http://stock.cngold.org/news/
常用函数:following-sibling::*
比如://span[@class=”page_curl”]/ following-sibling=a[1]
其中先找到数字页码1所在的位置为span,其class为page_url,这样就定位到了数字1所在的那个span。然后使用following-sibling找到其兄弟元素去定位下一页,找到其下一页也即是第2页所在的位置为a标签,由于后面所有同级元素的页码都是a标签,所以使用a[1]表示第1页后的第一个a标签。
“加载更多”的翻页形式
适用情况:
要采集的网页中,有“加载更多”或“再显示20条”等按钮,点击这些按钮之后需要采集的数据才会完全显示出来。
比如下列情况,需要点击“加载更多内容”,而且每点击一次多显示20条的数据:
https://weixin.sogou.com/
解决思路:
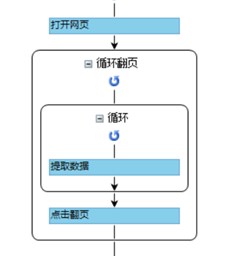
按照常规操作,创建翻页循环,然后将循环翻页步骤拖到循环-提取数据步骤前,让所有翻页完成之后,再进行循环提取数据步骤,不然会很多重复数据。
循环翻页的点击按钮一般是ajax加载,即点击翻页的高级选项需勾选ajax,并设置超时时间(时间长短根据数据加载快慢设置),不要勾选新标签。
比如,针对https://weixin.sogou.com/网页,常规的是先循环点击“加载更多内容”,比如下左图,如果这样执行采集数据之后,得到的将是前20条数据的循环采集。
对于此种情况,我们需要将循环提取数据拖到循环翻页下面,如右图,这样就会先将所有的数据都加在出来,再一起执行数据的提取了。注意,有时候数据太多,它会无限制地执行加载数据,此时可以对翻页设置循环次数限制。另外,需改变循环提取数据的xpath如下图,否则只能提取前20条数据。

网址:八爪鱼网络爬虫工具——学习笔记整理 https://www.yuejiaxmz.com/news/view/326352
相关内容
推荐这三款自动化爬虫软件,非常实用!不织布DIY可爱的八爪章鱼手工布艺制作教程
DeepLearning(深度学习)学习笔记整理.pdf资源
【听潮阁民间海味厨房】88元享门市价160元【A套餐=蛏子+花蚬子+鲍鱼+海虹+八爪鱼+小红贝+香螺+...】!
python爬虫代码
Deep Learning(深度学习)学习笔记整理系列之(四)
2024全网最全网络安全(自学)学习路线!整理了一个月!
网络安全(黑客)自学
爬山生活随笔(通用31篇)
网络学习心得体会
随便看看
最新动态分享
- 好设计点亮居家生活!家装沙龙助力业主打造理想家园
- 居家生活设计意图怎么写
- 居家适老化设计:让父母的晚年生活,安全又有温度
- 居家软装布置生活美学设计
- 成都【麓湖生态城C17青鸾屿】售楼电话
- 第三单元 居家生活防意外教学设计
- 我的居家设计花园生活游戏下载
- 成都【银河天悦云境】售楼处电话(最新已核验) | 8月参考总价一览 | 在售主力户型 | 优惠活动详情 | 特价房源 | 楼盘信息更新
- 《2026小红书年度居住趋势》发布:居住方式进入“适我时代”
- Decor Life
热点动态分享
- 145128
- 52569
- 45151
- 42515
- 40960
- 30931
- 25751
- 25545
- 21938
- 18670

