最简单的机器学习入门:线性回归
学习机器学习基础知识,如线性回归 #生活技巧# #工作学习技巧# #数字技能学习#
前言线性函数用来做回归、做分类其实是数学内容应用与时间的一个简单方法,其实这个高中生都可能会了解,只不过针对批样本用到了矩阵,会涉及到一些线性代数内容。让我们来了解一下这个数学背后的逻辑。
简单的y=wx+b直线函数表达式我们知道这是一关于x的直线函数,给出x的值就可以知道y是多少,思考这么一个问题:
正序逻辑:告诉你w、b的值,你就知道线性公式了,我们可以给出很多x的值,每个x值都有一个对应的y值反序逻辑:给你一些点<x,y>,你能告诉我w、b的值嘛?在生活中都是反序逻辑,台风跟季节、温度、湿度、地理位置等的关系,我们知道往年的这些指标,你要探讨这其中的关系,从而实现对未来的预测,根据关系找数值。
问题继续,我们的目标明确一下,就是找反序逻辑,找到w、b的值。还是拿简单的直线函数表达式来说,两个点可以表示一个直线,我们就可以确定一个直线,就可以求解w、b的值,所以我们需要两个样本,比如:
{ w + b = 3 2 w + b = 8 \left\{
w+b=32w+b=8" role="presentation">w+b=32w+b=8
\right. {w+b=32w+b=8高中知识就可以求解:w=5,b= - 2所以直线就是 y = 5 w − 2 y=5w-2 y=5w−2,这个是不是很简单,那么请迎接下面的问题。
思考:一条直线,100个<x,y>呢?这不扯淡嘛,2个<x,y>就可以确定一个直线,你给我那么多个<x,y>干嘛?问题来了,你怎么知道<x,y>就符合直线分布,不符合曲线呢?好吧,你这样讲,那我们根本就不知道公式形式是怎么样的,还这么求出表达式,那这样,大家各退一步,我们就规定一条直线,来求这个直线,看怎么把这个问题转化一下,于是有人提出:
找到一个直线,这条直线离各个<x,y>的距离之和最小。于是我们把这个问题数学化就是:
m i n δ = ∑ i 100 ∣ y i − y i ‘ ∣ y i ‘ = w x i + b min \qquad \delta = \sum_{i}^{100} |y_i-y^`_i| \\ y^`_i= wx_i +b minδ=i∑100∣yi−yi‘∣yi‘=wxi+b
其中, δ \delta δ就是误差函数,这个公式还是比较容易懂的吧,每一个x有对应的y,同时也有一个对应的 y ‘ y` y‘,可是 y ‘ y` y‘哪里来的呢?这开始了线性函数的算法求解。
这里用前后两次误差值来做终止条件,说明更新w、b已经不能减少误差,或者说对误差的减少帮助甚小,所以可以提前终止掉,上述流程中的步长系数、误差阈值都是可以调整的,按照自己的节奏。
思考:组成x的不是单独一个数值,而是一个向量?上一节的思考是从多样本单维度的角度思考,现在我们思考多样本、多维度的问题,在机器学习领域,提取特征是我们经常做的事情,比如我们做房屋售价预测,需要房屋面积、位置、户型、楼层等多维度的特征,这些才是组成一个样本,也就是说大多数情况下,样本是标示为: < x 1 , x 2 , x 3 , . . . x n , y > <x_1,x_2,x_3,...x_n,y> <x1,x2,x3,...xn,y>。特征有n个,y只有一个,这种情况跟我们上述的讨论有些差别,但我们知道多变量的线性表达式有如下形式:
y = w 1 x 1 + w 2 x 2 + w 3 x 3 + . . . + w n x n + b y=w_1x_1+w_2x_2+w_3x_3+...+w_nx_n+b y=w1x1+w2x2+w3x3+...+wnxn+b
这是一条样本的表示,通过线性代数的思想,如果我们有n个方程式,可以表示为:
y 1 y 2 ⋮ y n = x 11 x 12 ⋯ x 1 m x 21 x 22 ⋯ x 2 m ⋮ ⋯ ⋱ ⋮ x n 1 x n 2 ⋯ x n m w 1 w 2 ⋮ w m + b b ⋮ b
y1y2⋮yn=x11x12⋯x1mx21x22⋯x2m⋮⋯⋱⋮xn1xn2⋯xnmw1w2⋮wm+bb⋮b" role="presentation">y1y2⋮yn=x11x12⋯x1mx21x22⋯x2m⋮⋯⋱⋮xn1xn2⋯xnmw1w2⋮wm+bb⋮b
y1y2⋮yn=x11x21⋮xn1x12x22⋯xn2⋯⋯⋱⋯x1mx2m⋮xnmw1w2⋮wm+bb⋮b
这样把单个样本的误差提升到了多样本,从矩阵来求解,每一次的更新都通过矩阵运算,所以公式可以改为:
Y = W X + B Y=WX+B Y=WX+B
所以在很多博客里,求解都是通过上述极简公式用于表述问题。
我们知道里线性函数问题的求解问题形式是:
Y = W X + B Y=WX+B Y=WX+B
用梯度下降法要求导,为里利于求导计算,去掉绝对值符号,利用均方误差(MSE)替代:
1 m ∑ i = 1 m ( y i − y i ‘ ) 2 \frac{1}{m}\sum^{m}_{i=1}(y_{i} - y_{i}^`)^2 m1i=1∑m(yi−yi‘)2
修改一下的误差函数就是:
δ = 1 m ( Y − Y ‘ ) 2 \delta = \frac{1}{m}(Y - Y^`)^2 δ=m1(Y−Y‘)2
其实有时候想想一下,前面的系数 1 m \frac{1}{m} m1到底有没有用?我感觉没用,因为这个系数完全就是控制了大小,特别是求导的时候,我们看下,利用梯度下降法主要是有一个梯度方向,根据梯度方向,更新 w 、 b w、b w、b,是的 w 、 b w、b w、b的改变会让误差变小。那么 w 、 b w、b w、b的更新就变为:
W = W − λ ∂ δ ∂ W = W − 2 λ m X ∣ Y − Y ‘ ∣
W=W−λ∂δ∂W=W−2λmX|Y−Y‘|" role="presentation">W=W−λ∂δ∂W=W−2λmX|Y−Y‘|
W=W−λ∂W∂δ=W−m2λX∣Y−Y‘∣
b = b − λ ∂ δ ∂ b = b − 2 λ m ∣ Y − Y ‘ ∣
b=b−λ∂δ∂b=b−2λm|Y−Y‘|" role="presentation">b=b−λ∂δ∂b=b−2λm|Y−Y‘|
b=b−λ∂b∂δ=b−m2λ∣Y−Y‘∣
算法流程其他流程就跟上述的一样。这里我们一定要转换思路,这其实是一个二元函数,其中二元是指 w , b w,b w,b,不再是 X X X。转换角度来思考问题会让你更深的理解。
除了梯度下降法,其实还有最小二乘法,均方误差的一个方面就是为了最小二乘法,具体算法可以参考刘建平的算法博客最小二乘法
主要思想是对损失函数求偏导,令w、b偏倒数等于0,这样损失函数最小,并将公式推广到多样本维度,得到求解公式,主要涉及到的损失函数、求解函数如下:
J ( θ ) = 1 2 ( X θ − Y ) T ( X θ − Y ) W b = θ = ( X T X ) − 1 X T Y J(\theta)= \frac{1}{2}(X\theta-Y)^T(X\theta-Y)\\
Wb=θ=(XTX)−1XTY" role="presentation">Wb=θ=(XTX)−1XTY
J(θ)=21(Xθ−Y)T(Xθ−Y)Wb=θ=(XTX)−1XTY
其中, J ( θ ) J(\theta) J(θ)主要是由向量公式: a T a = ∑ i a i 2 a^Ta=\sum_{i}a_i^2 aTa=∑iai2演变而来, θ \theta θ中包含了 W 、 b W、b W、b,其中 X X X是 R m ∗ ( n + 1 ) \mathbb{R}^{m*(n+1)} Rm∗(n+1), Y Y Y是 R m ∗ 1 \mathbb{R}^{m*1} Rm∗1, W W W是 R n ∗ 1 \mathbb{R}^{n*1} Rn∗1, b b b是 R 1 \mathbb{R}^{1} R1。
其实是第一个元素是1,这个数表示的是b这个位置。有些博客不会加1,依旧认为 X X X是 R m ∗ ( n ) \mathbb{R}^{m*(n)} Rm∗(n),这是在公式里把1作为了一个特征,融入进来,与b相乘,符合公式。
优点:
全局最优解,其实不一定是全局最有解,有可能无解,但它还是能可以得到最优解。求解方便,公式直接求解。缺点:
受异常值扰动影响大,这可能是最大的影响。当样本特征n非常的大的时候,计算 X T X X^TX XTX的逆矩阵是一个非常耗时的工作(nxn的矩阵求逆),甚至不可行。此时以梯度下降为代表的迭代法仍然可以使用。大数据环境下建议超过10000个特征就用迭代法吧。或者通过主成分分析降低特征的维度后再用最小二乘法,一般都用牛顿迭代法。计算 X T X X^TX XTX的逆矩阵,有可能它的逆矩阵不存在,解决方法就是去掉冗余特征,让 X T X X^TX XTX的行列式不为0,这种情况下,梯度下降法依旧有效。如果拟合函数不是线性的,这时无法使用最小二乘法,需要通过一些技巧转化为线性才能使用,此时梯度下降仍然可以用。根据线性代数的知识:
当样本量m很少,小于特征数n的时候,这时拟合方程是欠定的,常用的优化方法都无法去拟合数据。当样本量m等于特征数n的时候,用方程组求解就可以了。当m大于n时,拟合方程是超定的,也就是我们常用与最小二乘法的场景了。 损失函数线性回归的损失函数可不只有均方误差,还有很多如下的损失函数,
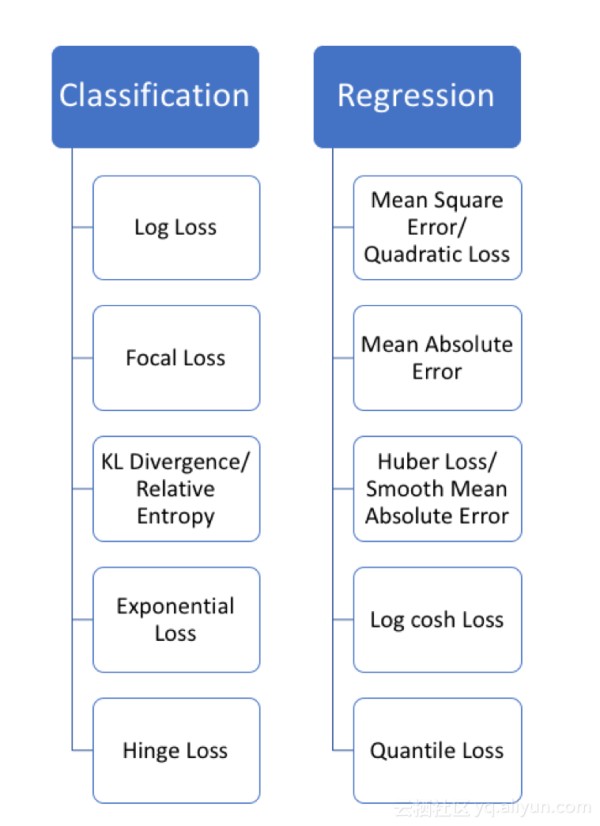
有时候为了防止过拟合,一般会加一个 L 1 L1 L1、 L 2 L2 L2范式。这里不做展开,具体展开会有专门的文章讲解。
社招、校招内推时刻
本人在阿里巴巴工作,业余时间做了社招、校招的公众号,可以内推大家,免筛选直接面试,公众号的一些文章也帮助大学、研究生的一些同学了解校招、了解名企,工作几年的同学想换工作也可以找我走社招内推,同时大家对文章有问题,也可以公众号找我,扫码关注哦!

线性回归原理小结
机器学习者都应该知道的五种损失函数!
网址:最简单的机器学习入门:线性回归 https://www.yuejiaxmz.com/news/view/330276
相关内容
机器学习——线性回归基础纯新手入门机器/深度学习自学指南(附一个月速成方案)
Python机器学习及实践——基础篇11(回归树)
机器学习与scikit
机器学习实战之数回归,CART算法
一文读懂!人工智能、机器学习、深度学习的区别与联系!
机器学习神器Scikit
回归预测
小白也能轻松学的计算机网络零基础入门(附学习路线 + 计算机网络教程)
最新新手学习烹饪的入门方法
随便看看
最新动态分享
- 家庭消毒不用愁!5大物理消毒法守护健康生活
- カビをアルコール退治|消毒用エタノールでの除菌方法やNG使用法も
- 消毒产品目录
- 基于STM32的智能鞋柜控制系统设计与实现
- 【解決】家具に生えたカビの取り方、予防法、原因を紹介
- 抗菌实验不同操作方法及细节对试验结果的影响
- 多部门推动物联网创新发展 到2028年这些技术要突破
- 生活区节水节电节能管控措施.docx
- 家庭节约用电有哪些具体方法?
- 北京市出台碳普惠管理办法 市民低碳行为将能“变现”
热点动态分享
- 145110
- 52417
- 45122
- 42498
- 40935
- 30916
- 25711
- 25537
- 21925
- 18632

