初学大数据技术与应用学习心得
持续学习:跟进新技术,如AI和大数据 #生活技巧# #工作学习技巧# #编程学习路径#
作为一名初涉大数据领域的大学生,我近期参加了大数据技术与应用课程的学习。这段学习经历不仅让我对大数据有了更加全面和深入的理解,还让我掌握了一系列实用的数据分析技能。以下是我对大数据分析概述、大数据分析平台、数据挖掘概念与工程、数据预处理与特征工程、关联规则、分类分析、回归分析以及聚类分析等关键内容的学习心得。
一、大数据分析概述大数据,简而言之,是指无法在较短时间内用传统数据库软件工具进行捕捉、管理和处理的数据集合。它具有数据量大、类型繁多、处理速度快和价值密度低等特点。在当今信息爆炸的时代,大数据已成为各行各业的重要资源,其应用渗透到商业、医疗、教育、金融等众多领域。
学习大数据分析,首先让我认识到,大数据的价值不仅在于数据本身,更在于如何挖掘和应用这些数据。大数据分析通过先进的计算技术和算法,可以从海量数据中提取出有价值的信息,为企业和个人提供决策支持。这一认识让我对大数据的前景充满期待,也激发了我深入学习的热情。
二、大数据分析平台大数据分析平台是进行大数据分析的基础设施,它提供了数据存储、数据处理、数据分析和数据可视化的功能。在课程中,我们学习了Hadoop、Spark、Hive等主流的大数据处理框架和工具。
Hadoop是一个分布式文件系统(HDFS)和分布式计算框架(MapReduce)的结合体,它允许用户在不需要了解分布式底层细节的情况下,开发分布式程序。Hadoop的分布式存储和计算能力,使其成为处理大规模数据的重要工具。
Spark则是基于内存的分布式计算系统,其计算速度比Hadoop快得多,特别是在迭代计算和实时分析方面表现出色。Hive则是一个建立在Hadoop之上的数据仓库工具,它提供了类似SQL的查询语言(HiveQL),使得用户可以更方便地进行数据查询和分析。
通过学习和实践这些大数据分析平台,我深刻体会到,选择合适的大数据分析平台,对于提高数据处理的效率和准确性至关重要。
三、数据挖掘概念与工程数据挖掘是指从大型数据集中提取隐含的、先前未知的、有潜在价值的模式或信息的过程。数据挖掘工程则是一个系统性的过程,包括数据收集、数据预处理、数据挖掘、模式评估和知识表示等步骤。
在学习过程中,我了解到数据挖掘的常用技术包括关联分析、分类分析、回归分析、聚类分析等。每一种技术都有其特定的应用场景和优势,例如,关联分析可以发现商品之间的关联关系,帮助商家进行商品推荐;分类分析可以对数据进行分类,用于预测新数据的类别;回归分析则可以揭示变量之间的依赖关系,用于预测数值型数据。
数据挖掘工程的实践性很强,它要求我们在掌握理论知识的同时,具备解决实际问题的能力。通过参与课程中的项目实践,我学会了如何运用数据挖掘技术解决实际问题,这对我的能力提升有很大的帮助。
四、数据预处理与特征工程数据预处理是数据挖掘过程中的一个重要环节,它包括对数据进行清洗、集成、变换和归约等操作。数据清洗可以去除数据中的噪声和异常值,提高数据质量;数据集成可以将多个数据源的数据合并在一起,形成统一的数据视图;数据变换可以改变数据的表示形式,使其更适合分析;数据归约则可以减少数据的维度和数量,降低计算复杂度。
特征工程则是数据挖掘中的另一个关键步骤,它涉及特征选择、特征提取和特征构造等操作。特征选择是从原始特征中选择出对预测目标最有用的特征;特征提取则是通过一定的方法将原始特征转换为新的特征;特征构造则是根据实际需求,创造新的特征。
数据预处理和特征工程对于数据挖掘的结果有着至关重要的影响。通过学习和实践,我深刻体会到,在进行数据挖掘之前,必须认真进行数据预处理和特征工程,以确保数据的准确性和有效性。
五、关联规则关联规则是数据挖掘中的一种重要技术,它用于发现数据集中不同项之间的关联关系。在零售、电子商务等领域,关联规则被广泛应用于商品推荐、库存管理等方面。
学习关联规则的过程中,我了解到Apriori算法和FP-Growth算法是两种常用的关联规则挖掘算法。Apriori算法通过多次扫描数据集,逐步生成频繁项集,然后从中提取关联规则;FP-Growth算法则通过构建频繁模式树(FP-Tree),直接在树上进行频繁项集的挖掘,从而提高了算法的效率。
通过实践,我掌握了关联规则挖掘的基本方法和步骤,并成功将其应用于实际问题的求解中。这让我深刻体会到,关联规则挖掘在解决实际问题中的重要作用。
使用Apriori算法进行关联规则挖掘首先,我们需要安装mlxtend库,这个库提供了Apriori算法的实现。
bash复制代码
以下是一个使用Apriori算法进行关联规则挖掘的示例代码:
python复制代码
import pandas as pd from mlxtend.frequent_patterns import apriori, association_rules # 示例数据集 dataset = [['牛奶', '面包', '黄油'], ['啤酒', '面包'], ['牛奶', '尿布', '啤酒', '可乐'], ['面包', '牛奶', '尿布', '啤酒'], ['面包', '牛奶'], ['可乐', '牛奶'], ['面包', '黄油', '牛奶']] # 将数据集转换为One-Hot编码的DataFrame one_hot = pd.get_dummies(pd.DataFrame(list(map(set, dataset)))) # 计算频繁项集,设置最小支持度阈值为0.2 frequent_itemsets = apriori(one_hot, min_support=0.2, use_colnames=True) # 计算关联规则,设置最小置信度阈值为0.5 rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5) # 打印结果 print("频繁项集:") print(frequent_itemsets) print("\n关联规则:") print(rules[['antecedents', 'consequents', 'support', 'confidence']]) 使用FP-Growth算法进行关联规则挖掘同样,我们需要安装mlxtend库,因为它也提供了FP-Growth算法的实现。
以下是一个使用FP-Growth算法进行关联规则挖掘的示例代码:
python复制代码
from mlxtend.frequent_patterns import fpgrowth, association_rules # 示例数据集(与Apriori算法相同) dataset = [['牛奶', '面包', '黄油'], ['啤酒', '面包'], ['牛奶', '尿布', '啤酒', '可乐'], ['面包', '牛奶', '尿布', '啤酒'], ['面包', '牛奶'], ['可乐', '牛奶'], ['面包', '黄油', '牛奶']] # 将数据集转换为FP-Growth算法可以处理的格式 transactions = [list(map(frozenset, [set(item) for item in dataset]))] # 计算频繁项集,FP-Growth算法不需要设置最小支持度阈值,但可以通过min_support进行剪枝 frequent_itemsets = fpgrowth(transactions, min_support=0.2, use_colnames=False) # 计算关联规则,设置最小置信度阈值为0.5 rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5) # 打印结果 print("频繁项集:") print(frequent_itemsets) print("\n关联规则:") print(rules[['antecedents', 'consequents', 'support', 'confidence']]) 注意事项 数据预处理:在实际应用中,数据预处理是非常重要的一步,包括数据清洗、数据转换等。参数选择:最小支持度(min_support)和最小置信度(min_threshold)等参数的选择需要根据具体问题进行调整。结果解释:挖掘出的关联规则需要进行解释和验证,以确保其在实际应用中的有效性。 六、分类分析分类分析是数据挖掘中的一种常见任务,它根据已知的训练数据集,学习出一个分类模型,然后使用该模型对新数据进行分类预测。常见的分类算法包括决策树、支持向量机、朴素贝叶斯等。
学习分类分析的过程中,我深刻体会到不同分类算法的特点和适用场景。例如,决策树算法具有直观易懂、易于解释的优点,但容易过拟合;支持向量机算法在处理高维数据和非线性数据时表现出色,但计算复杂度较高;朴素贝叶斯算法则适用于处理具有特征之间相互独立假设的数据。
通过实践,我学会了如何选择合适的分类算法,并根据实际需求对算法进行调优,以提高分类的准确性和效率。
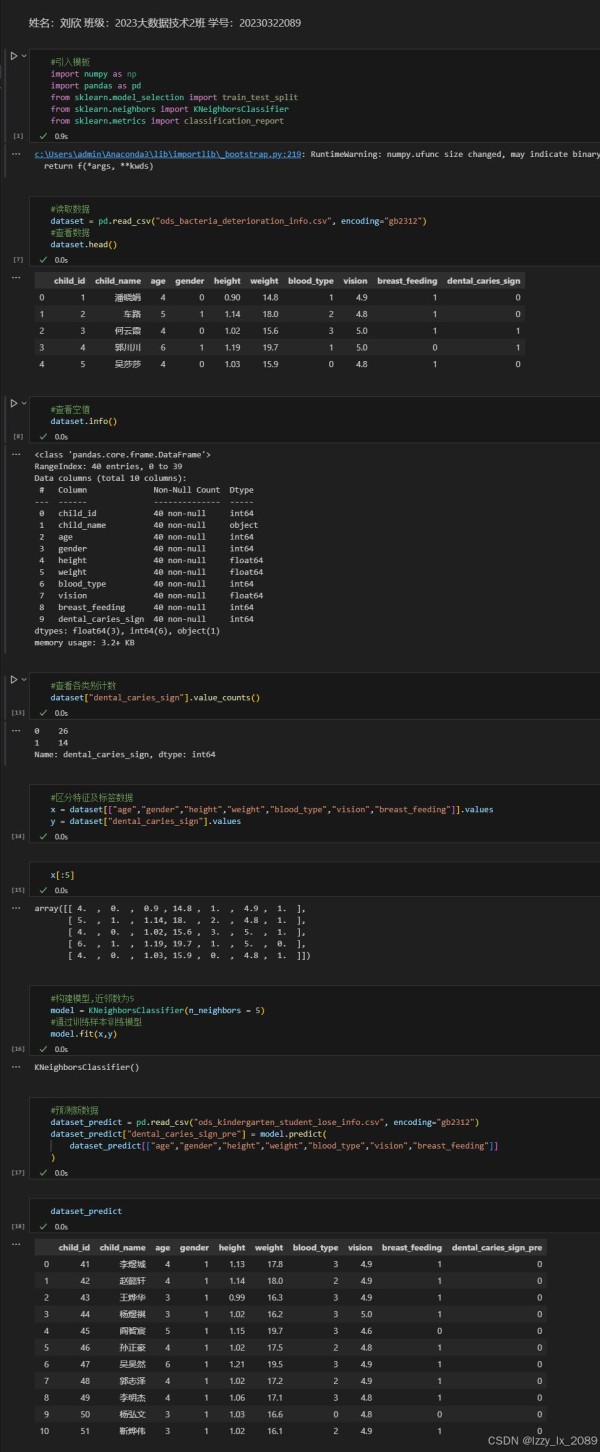
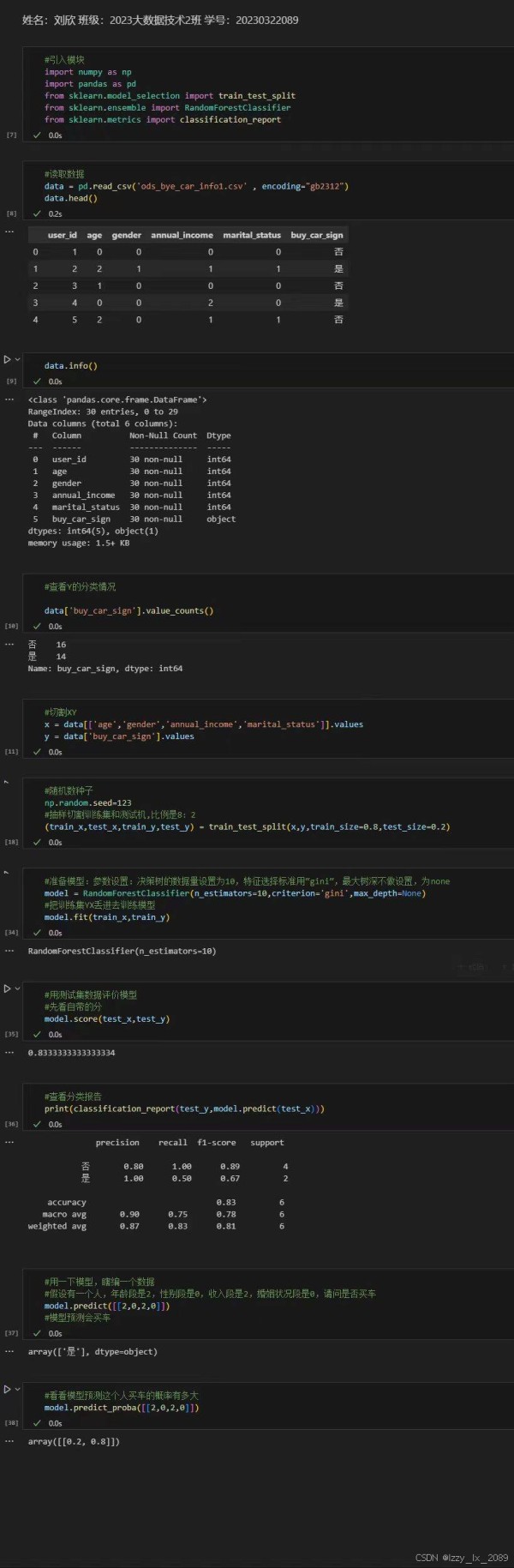
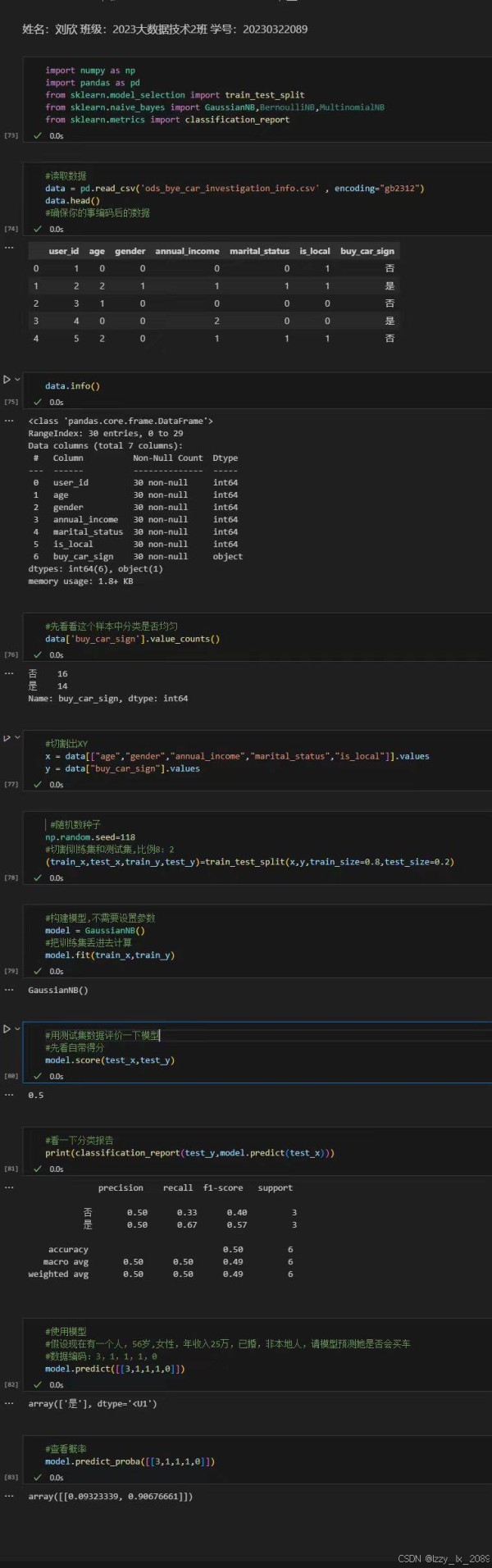
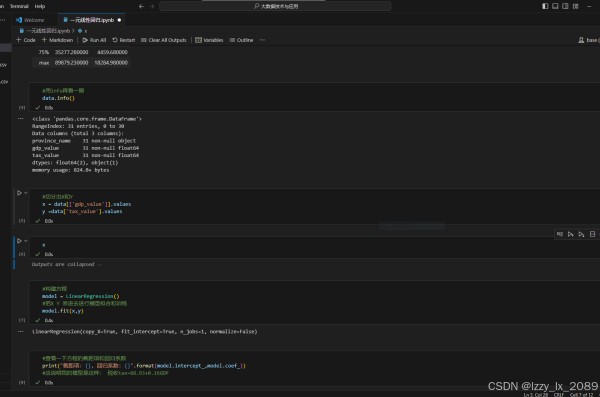
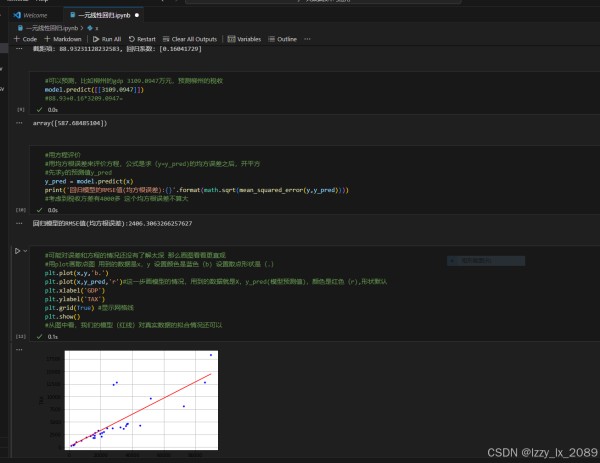
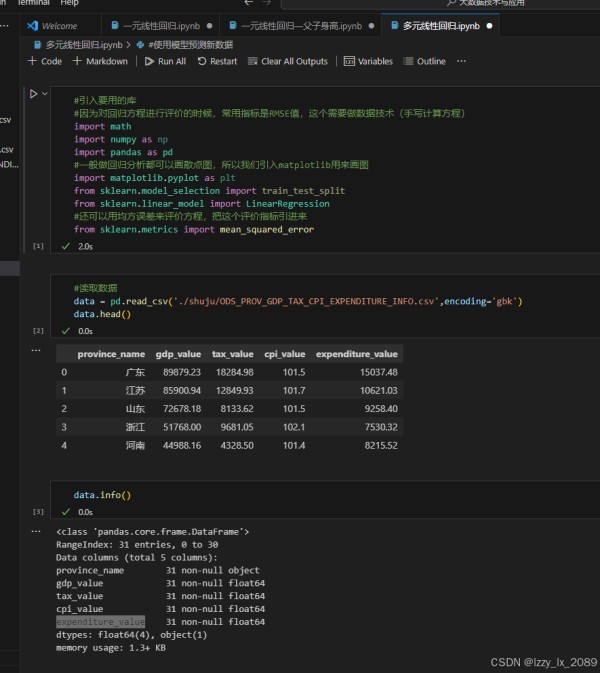
回归分析是数据挖掘中的一种重要技术,它用于揭示变量之间的依赖关系,并预测数值型数据。常见的回归分析方法包括线性回归、非线性回归、逻辑回归等。
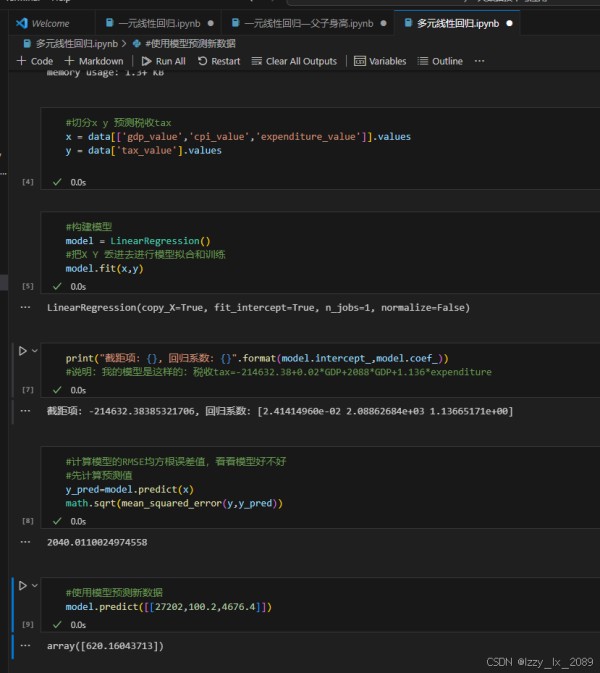
学习回归分析的过程中,我了解到线性回归是最简单、最常用的回归分析方法之一。它通过建立自变量和因变量之间的线性关系模型,对数据进行拟合和预测。非线性回归则用于处理自变量和因变量之间呈非线性关系的情况。逻辑回归则是一种特殊的回归分析方法,它主要用于二分类问题的求解。
通过实践,我学会了如何运用回归分析方法对数据进行拟合和预测,并掌握了如何评估回归模型的好坏。这让我深刻体会到,回归分析在解决实际问题中的重要作用。
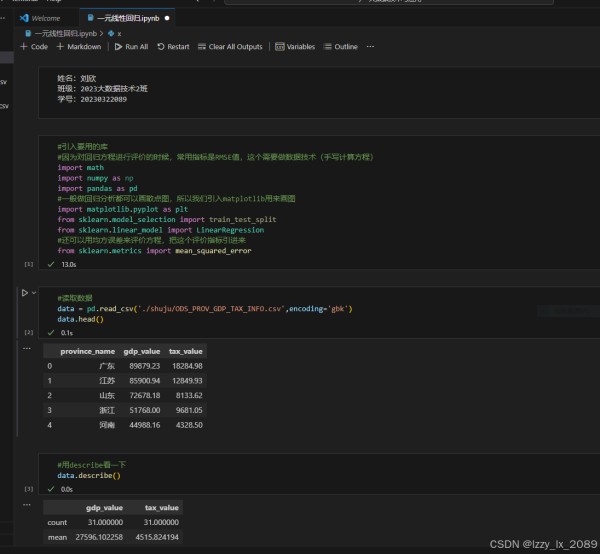
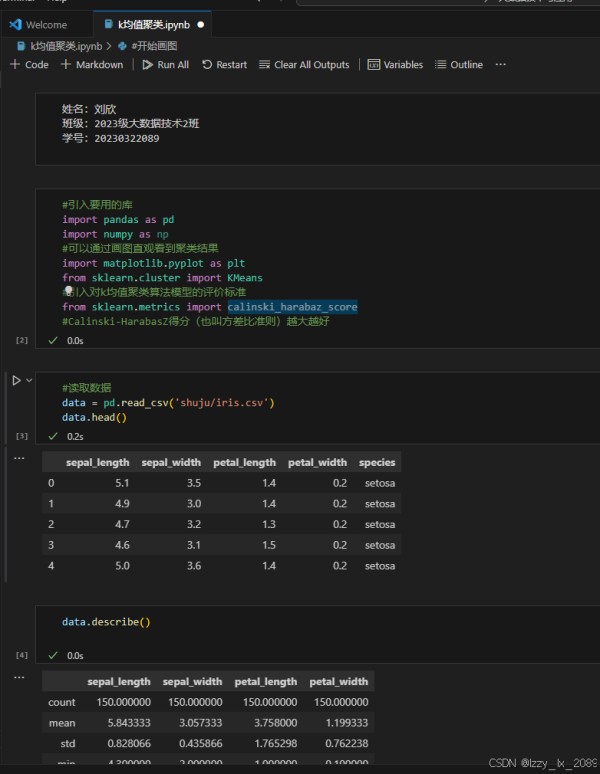
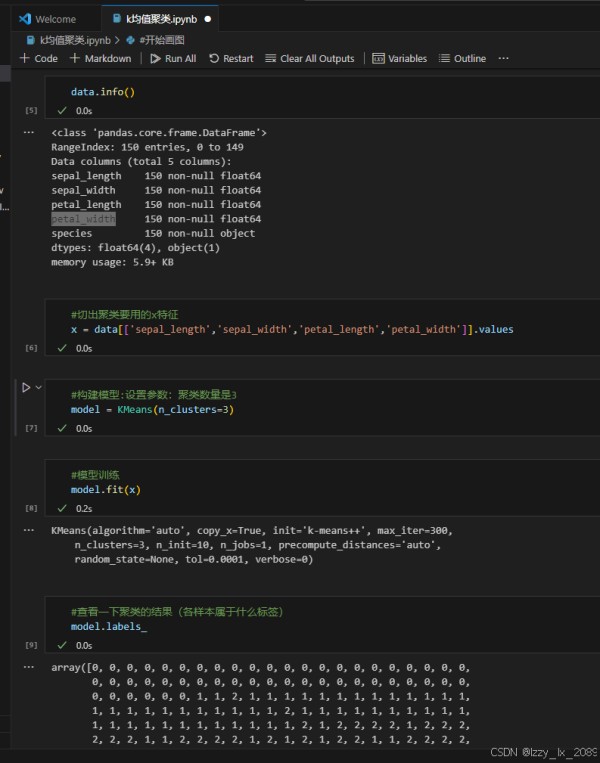
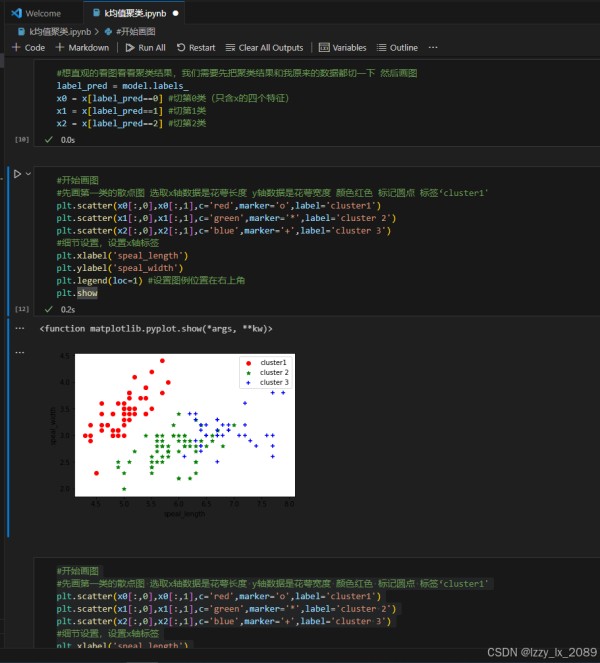
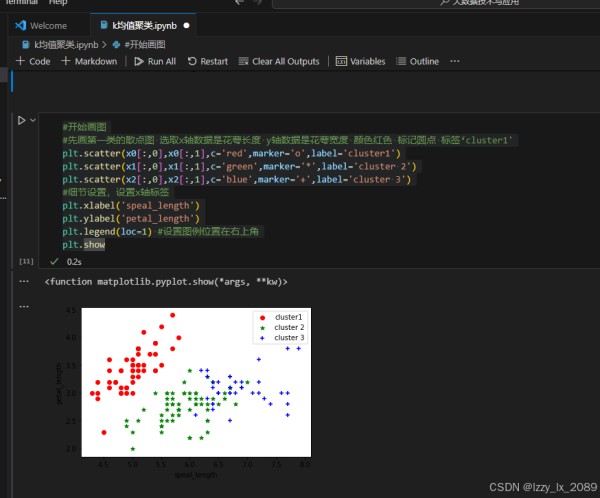
聚类分析是数据挖掘中的一种无监督学习方法,它根据数据的相似性将数据集划分为多个簇,使得同一个簇内的数据彼此相似,而不同簇之间的数据差异较大。常见的聚类算法包括K-means、层次聚类、DBSCAN等。
学习聚类分析的过程中,我了解到K-means算法是一种简单、快速的聚类算法,它适用于处理大规模数据集。层次聚类算法则通过构建层次树(聚类树)的方式,逐步进行聚类操作。DBSCAN算法则是一种基于密度的聚类算法,它可以发现任意形状的簇。
通过实践,我学会了如何运用聚类分析方法对数据进行划分和聚类,并掌握了如何评估聚类结果的好坏。这让我深刻体会到,聚类分析在解决实际问题中的重要作用。
通过这段时间的学习和实践,我对大数据技术与应用有了更加全面和深入的理解。我掌握了大数据分析平台的使用、数据挖掘的基本方法和步骤、数据预处理和特征工程的重要性、关联规则、分类分析、回归分析和聚类分析等关键技术的原理和应用。
这段学习经历不仅提升了我的专业技能,还培养了我解决实际问题的能力。我相信,在未来的学习和工作中,我将能够运用所学知识,更好地解决实际问题,为大数据领域的发展贡献自己的力量。
网址:初学大数据技术与应用学习心得 https://www.yuejiaxmz.com/news/view/807314
相关内容
网络技术学习心得(八篇)大数据平台开发学习路线及技能
数字支付的技术创新:AI与机器学习在支付中的应用
电子技术学习心得体会(通用18篇)
电子技术学习心得体会
电子技术学习心得体会(精选11篇)
大数据教育智能化与个性化学习
数字化教学学习心得感悟5篇
AI技术在大数据分析中的应用.pptx
艺术与身心健康初中美术学习中的压力释放与调节.pptx
随便看看
最新动态分享
- 家庭消毒不用愁!5大物理消毒法守护健康生活
- カビをアルコール退治|消毒用エタノールでの除菌方法やNG使用法も
- 消毒产品目录
- 基于STM32的智能鞋柜控制系统设计与实现
- 【解決】家具に生えたカビの取り方、予防法、原因を紹介
- 抗菌实验不同操作方法及细节对试验结果的影响
- 多部门推动物联网创新发展 到2028年这些技术要突破
- 生活区节水节电节能管控措施.docx
- 家庭节约用电有哪些具体方法?
- 北京市出台碳普惠管理办法 市民低碳行为将能“变现”
热点动态分享
- 145110
- 52352
- 45120
- 42490
- 40934
- 30915
- 25700
- 25536
- 21924
- 18627

