Sklearn中主成分分析(PCA)在Iris数据集上的应用
参加数据分析认证,如数据分析上岗证或数据分析师证书 #生活技巧# #工作学习技巧# #技能培训认证#
iris数据集:
iris数据集从sklearn中获取,其csv文件地址...\Lib\site-packages\sklearn\datasets\data\iris.csv
最初接触主成分分析是在数学建模中,旨在以较少的新指标来替换原来较多的旧指标,换句话说就是对高维空间进行降维处理。
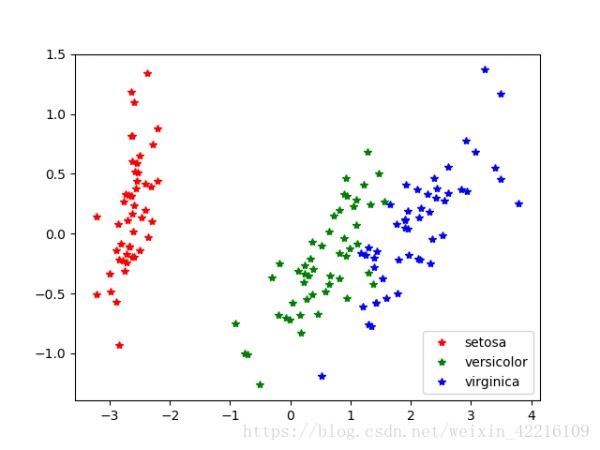
Iris数据集是常用的分类实验数据集,包括150个样本,分为3类(Setosa,Versicolour,Virginica)。每个样本包括花萼长度,花萼宽度,花瓣长度,花瓣宽度4个特征。由于样本特征已经属于高维数据,不便以图解形式分类。为了直观上对3种鸢尾花的分类有一个感性的认识,我们可以通过PCA降维处理,使其样本只包含两个新特征。
函数原型及主要参数说明
class sklearn.decomposition.PCA(n_components=None)
参数说明:
n_components : 类型:int, float, None or string
含义:所要保留的主成分个数(Number of components to keep)。
函数方法
fit_transform(self, X, y=None)
参数说明:
X:训练数据X_train,并且X_train.shape(n_samples, n_features)(注:n_features为原样本的特征个数)
y : Ignored.
返回:
X_new : X_new.shape (n_samples, n_components )(注:n_components为设置保留的主成分个数)
应用
直接附上基于python的代码。
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
iris=load_iris()
pca=PCA(n_components=2)
trans_data=pca.fit_transform(iris.data)
index1=np.where(iris.target==0)
index2=np.where(iris.target==1)
index3=np.where(iris.target==2)
labels=['setosa', 'versicolor', 'virginica']
plt.plot(trans_data[index1][:,0],trans_data[index1][:,1],'r*')
plt.plot(trans_data[index2][:,0],trans_data[index2][:,1],'g*')
plt.plot(trans_data[index3][:,0],trans_data[index3][:,1],'b*')
plt.legend(labels)
plt.show()
最后附上效果图,可以发现通过PCA降维处理能直观上对数据进行分类,并且在Iris数据集上有较好的体现。
网址:Sklearn中主成分分析(PCA)在Iris数据集上的应用 https://www.yuejiaxmz.com/news/view/963567
相关内容
PCA (主成分分析)详解 (写给初学者) 结合matlab数据分享|R语言、SPSS基于主成分PCA的中国城镇居民消费结构研究可视化分析
【sklearn
人工智能与大数据分析的实例研究
生活中数据分析应用案例分享,生活中数据分析应用案例
数据分析在生活中的新应用
巨细!一文告诉你数据分析不得不知的秘密!
生活中数据分析应用案例分享,数据分析在生活中的奇妙应用,揭秘日常生活中的数据魔法
生活中的数据分析案例,生活中数据分析应用案例
AI技术在大数据分析中的应用.pptx
随便看看
最新动态分享
- 中医养生100条秘籍:掌握这些,健康长寿不是梦!
- 餐饮/旅游/美食网站源码
- 如何一键开启画中画模式:Chrome扩展终极指南
- 关于2025年湖南省优秀科普作品、科普项目立项名单的公示
- 和存在感薄弱妹妹一起的简单生活0.99安装包手游中文完整版下载安装2026最新版本
- 关于2026年湖南省科普项目(第一批)立项名单的公示
- 【Brain Puzzle: Tricky Quest】攻略・謎解きの答え:1~6ページ目のステージ
- 健康生活指南:简单实用的日常建议
- 全家适的健康生活指南,口腔到睡眠全覆盖,建议收藏慢慢看
- 【50条健康知识】践行健康生活方式在每一天
热点动态分享
- 145038
- 51841
- 45038
- 42424
- 40840
- 30842
- 25558
- 25474
- 21845
- 18548

