数据分析在生活中的新应用
大数据分析在商业决策中的应用,源于科技创业的创新应用 #生活知识# #生活感悟# #科技生活变迁# #科技创业#
现如今,我们的生活已高度数字化,各类数据分析工具正在潜移默化影响我们的生活,今天海文集团教研团队带来的是一项通过数据分析判断电影口碑的小实验。
原文CSDN博客地址:https://link.zhihu.com/?target=https%3A//blog.csdn.net/qq_52417436/article/details/131565367%3Fspm%3D1001.2014.3001.5501
在此实验中我们将对电影《消失的她》的豆瓣短评数据进行分析。我们的目标是通过对评论数据的探索性数据分析(EDA),情感分析和影评分析,来了解观众对这部电影的评价,以及这部电影是否值得观看。
我们将使用的数据包括:
《消失的她》豆瓣短评数据.csv :这是我们的主要数据,包含了豆瓣用户对电影《消失的她》的短评。
停用词库.txt:这是我们用来进行文本预处理的停用词库,包含了一些在分析中需要被忽略的常见词汇。
1、数据加载和预处理
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv('《消失的她》豆瓣短评数据 .csv')
# 查看数据的基本信息
df.info()
df.head()
输出:
<class'pandas.core.frame.DataFrame'>
RangeIndex: 232 entries, 0 to 231
Data columns (total 6 columns):
Column Non-Null Count Dtype
0 评论者网名 220 non-null object
1 评价 217 non-null object
2 评论 220 non-null object
3 评论时间 220 non-null object
4 评论地点 220 non-null object
5 评论点赞数 220 non-null float64
dtypes: float64(1), object(5)
memory usage: 11.0+ KB

从上面的输出中,我们可以看到数据集包含232条记录,每条记录包含6个字段:
评论者网名:评论者的用户名评价:评论者对电影的评价,例如'推荐' ,'还行'等评论:评论者对电影的具体评论评论时间:评论发布的时间评论地点:评论者的地理位置评论点赞数:该评论获得的点赞数我们可以看到,有些字段存在缺失值,例如'评论者网名' ,'评价' ,'评论' ,'评论时间','评论地点'和'评论 点赞数'。在进行进一步的分析之前,我们需要处理这些缺失值。
df = df.dropna()
df.info()
df.head()
输出:
<class'pandas.core.frame.DataFrame'>
Int64Index: 217 entries, 0 to 229
Data columns (total 6 columns):
Column Non-Null Count Dtype
0 评论者网名 217 non-null object
1 评价 217 non-null object
2 评论 217 non-null object
3 评论时间 217 non-null object
4 评论地点 217 non-null object
5 评论点赞数 217 non-null float64
dtypes: float64(1), object(5)
memory usage: 11.9+ KB

通过删除包含缺失值的行,我们现在有217条完整的记录。下一步,我们将进行探索性数据分析( EDA )。
2、探索性数据分析(EDA )
在这一部分,我们将对数据进行初步的探索,包括:
这将帮助我们了解观众对电影的整体评价,以及评论的一些基本特征。
df['评价 '].value_counts()
输出:
还行 63
推荐 54
较差 47
很差 38
力荐 15
Name: 评价, dtype: int64
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
# 设置风格
sns.set_style('whitegrid')
# 示例数据
cate = [str(i) for i in df['评价 '].value_counts().index]
data = [int(i) for i in df['评价 '].value_counts().values]
pie = (Pie()
.add('', [list(z) for z in zip(cate, data)],
radius=["30%", "75%"],
rosetype="radius"
)
.set_global_opts(title_opts=opts.TitleOpts(title="《消失的她》评价", subtitle="总体分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) )
pie.render_notebook()
输出:
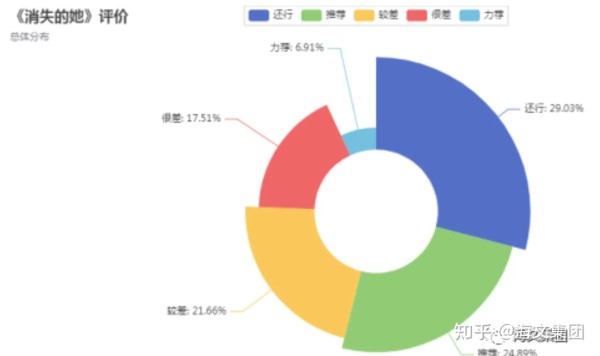
从上图中,我们可以看到大部分的评论都是'还行' ,其次是'推荐' ,这说明大部分观众对这部电影的评价还是比较积极的。
接下来,我们来看一下评论点赞数的分布。
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
df['评论点赞数 '].describe()
sns.distplot(df['评论点赞数 '], bins=20, kde=False)
AxesSubplot:xlabel='评论点赞数'
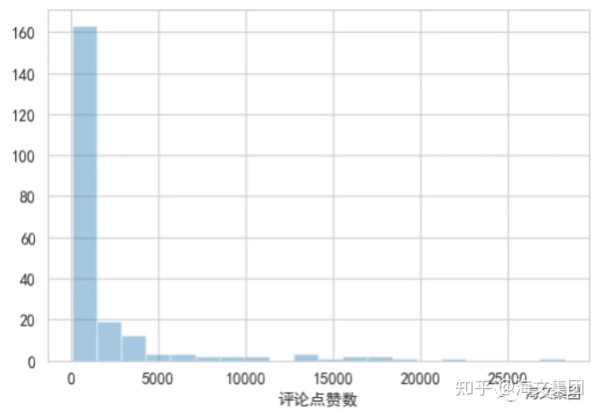
从上图中,我们可以看到评论点赞数的分布是右偏的,大部分的评论点赞数都在10000以下,只有少数的评论点赞数超过10000。这说明虽然有些评论得到了很多的点赞,但大部分的评论只得到了较少的点赞。
接下来,我们来看一下评论的地理分布。
# 查看评论的地理分布
plt.figure(figsize=(10, 8))
sns.countplot(y='评论地点 ', data=df, order=df['评论地点 '].value_counts().index) plt.title('评论的地理分布 ')
plt.xlabel('数量 ')
plt.ylabel('地点 ')
plt.show()
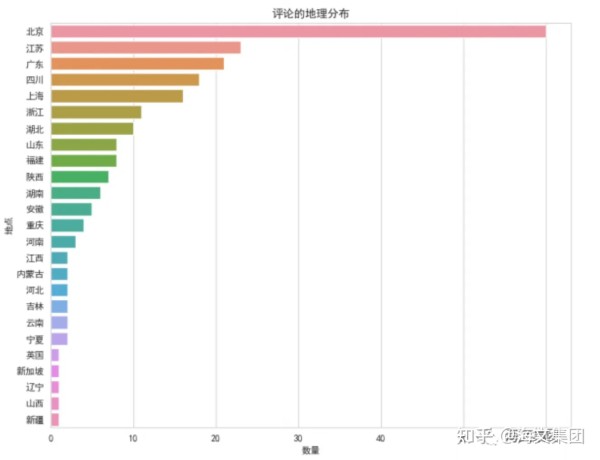
从上图中,我们可以看到评论主要来自于北京、上海、广东和江苏等地,这些地方的观众活跃度较高。
通过以上的探索性数据分析,我们对数据有了一定的了解。接下来我们将进行情感分析,以了解观众对电影的情感倾向。
3、情感分析
在这一部分,我们将对评论文本进行情感分析,以了解观众对电影的情感倾向。我们将使用jieba库进行 中文分词,然后使用SnowNLP库进行情感分析。
首先,我们需要加载停用词库,并定义一个函数来进行文本预处理。
import jieba
from snownlp import SnowNLP
with open('停用词库 .txt', 'r', encoding='utf-8') as f:
stop_words = [line.strip() for line in f.readlines()]
def preprocess_text(text):
words = jieba.cut(text)
words = [word for word in words if word not in stop_words] return ' '.join(words)
df['评论 '] = df['评论 '].apply(preprocess_text)
df['评论 '].head()
输出:
0 一个 谋杀 老婆 男人 无意 谋杀 孩子 流泪 讽刺
1 倪妮 角色 T 铁 T 复仇记
2 男主 b 超 照片 崩溃 孩子 杀 老婆 眼都 眨 ...
3 建议 情人节 档 安排 适合 情侣 宝宝 好 电影 ❤ ...
4 故事 20 分钟 猜 表演 倪妮 好似 没什么 信念 感...
Name: 评论, dtype: object
我们已经成功地对评论进行了预处理,接下来我们将进行情感分析。我们将使用SnowNLP库来进行情感分析。SnowNLP的情感分析是基于情感倾向分类,它会返回一个0到1之间的浮点数,数值越接近1,表示情感越积极,越接近0 ,表示情感越消极。
from snownlp import SnowNLP
def sentiment_analysis(text):
return SnowNLP(text).sentiments
df['情感分析 '] = df['评论 '].apply(sentiment_analysis)
df['情感分析 '].head()
输出:
0 0.999920
1 0.998887
2 0.054732
3 0.905509
4 0.923089
Name: 情感分析, dtype: float64
import matplotlib.pyplot as plt
# 绘制情感分析结果的直方图
plt.hist(df['情感分析 '], bins=20, alpha=0.5, color='steelblue', edgecolor='black') plt.title('情感分析结果 ')
plt.xlabel('情感倾向 ')
plt.ylabel('评论数量 ')
plt.show()
输出:
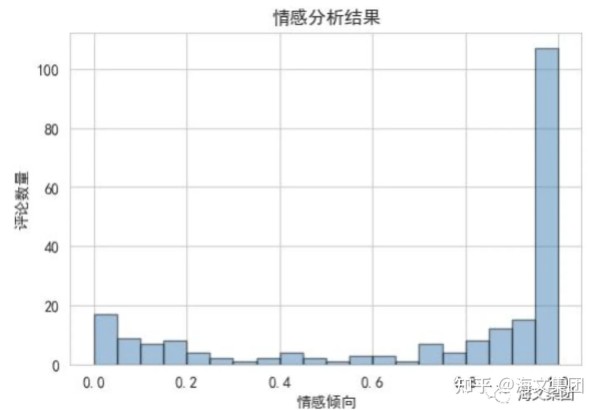
从直方图中我们可以看出,大部分的评论都倾向于积极的情感,这说明观众对这部电影的评价普遍较好。
from wordcloud import WordCloud
# 合并所有评论
text = ' '.join(df['评论 '])
# 生成词云
wordcloud = WordCloud(font_path='simhei.ttf',
background_color='white').generate(text)
# 显示词云
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
输出:

从词云中,我们可以看到评论中出现频率较高的词,这些词可以帮助我们理解观众对电影的主要评论主题。
接下来,我们将对电影的评分进行分析,我们将计算电影的平均评分,并查看评分的分布情况。
# 将 '评价 '这一列的数据转换为数值
df['评价 '] = df['评价 '].map({'很差 ': 1, '较差 ': 2, '还行 ': 3, '推荐 ': 4, '力荐 ': 5})
# 计算电影的平均评价
average_rating = df['评价 '].mean()
print(f'电影的平均评价是:{average_rating:.2f}')
# 绘制评价的直方图
plt.hist(df['评价 '], bins=5, alpha=0.5, color='steelblue', edgecolor='black') plt.title('评价分布 ')
plt.xlabel('评价 ')
plt.ylabel('评论数量 ')
plt.show()
电影的平均评价是:2.82
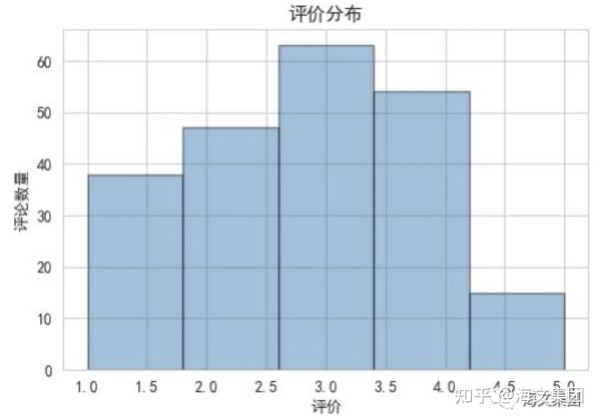
电影的平均评价是2.82,这说明观众对电影的评价普遍偏向于"还行"和"推荐"。从评价的分布图中,我们可以看到大部分的评价都集中在"还行"和"推荐"这两个级别,这进一步证实了观众对电影的评价普遍较好。
综上所述,从情感分析的结果、评论的词云和电影的评价来看,观众对这部电影的评价普遍较好,因此,这部电影值得我们去看。
网址:数据分析在生活中的新应用 https://www.yuejiaxmz.com/news/view/202862
相关内容
生活中的数据分析日常生活中,数据分析最常应用的4大场景
生活中的什么数据可以做数据分析
生活中的数据分析(转载)
大数据在生活中有什么应用(一)
【大数据分析对现代生活的作用】
11个大数据在日常生活中的应用场景
生存数据分析
【数据分析】15组Excel函数,解决数据分析中80%的难题!
人人都是数据分析师:到底什么是数据分析?如何进行数据分析?
随便看看
最新动态分享
- 家庭消毒不用愁!5大物理消毒法守护健康生活
- カビをアルコール退治|消毒用エタノールでの除菌方法やNG使用法も
- 消毒产品目录
- 基于STM32的智能鞋柜控制系统设计与实现
- 【解決】家具に生えたカビの取り方、予防法、原因を紹介
- 抗菌实验不同操作方法及细节对试验结果的影响
- 多部门推动物联网创新发展 到2028年这些技术要突破
- 生活区节水节电节能管控措施.docx
- 家庭节约用电有哪些具体方法?
- 北京市出台碳普惠管理办法 市民低碳行为将能“变现”
热点动态分享
- 145095
- 52201
- 45097
- 42473
- 40907
- 30882
- 25663
- 25527
- 21903
- 18601

