L:python的Pandas模块:字符串处理,分组统计,数据透视表,时间序列
数据分析:Python的Pandas库数据处理 #生活知识# #编程教程#
字符串处理
Pandas为字符串提供了形如“obj.str.方法()”的一系列命令支持,这些方法一般在数据清洗、转换时使用。
s = Series(['Beauty and the Beast', 'Captain America: Civil War', 'Jurassic World', 'Toy Story']) help(s.str)# 显示 s.str帮助 s.str.len()# 返回字符串长度 s.str.split()# 分割字符串 s.str[:6]# 字符串切片 s.str.contains('War') # 测试电影名中是否包含War s.str.lower().str.contains('war') # 转小写再测是否含war s.str.replace(' ', '-')# 字符替换,用横线- 替换空格
python
运行

分组统计
Pandas支持数据分组,功能类似数据库中的group by(分组统计)。
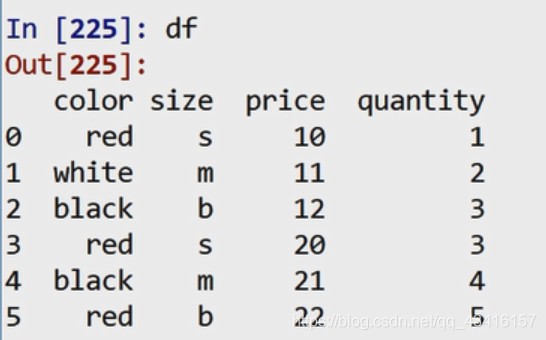
df = pd.DataFrame({'color': ['red', 'white', 'black', 'red', 'black', 'red'], 'size': ['s','m','b','s','m','b'], 'price': [10, 11, 12, 20, 21, 22], 'quantity': [1, 2, 3, 3, 4, 5]})
python
运行
g = df.groupby('color') # 按color分组 g是一个DataFrameGroupBy对象,它实际上还没有进行任何分组统计, 仅含有一些分组如何划分的关键信息。分组键有多种形式: 某个列或列的组合。 列表或数组,其长度与待分组的轴⼀样 字典或Series,给出待分组轴上的值与分组名之间的对应关系。 函数,用于处理数据或标签。
python
运行
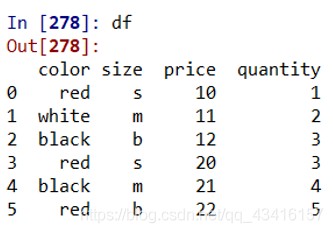
分组对象的属性和方法
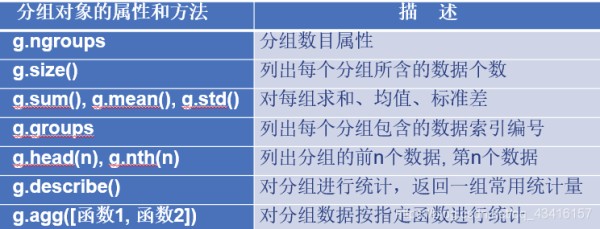
g.ngroups# ngroups分组数 g.groups# 列出每个分组包含的数据索引编号 for name, group in g: print(name)# 输出组名 print(group)# 组内容 g.size()# 列出每个分组的数据条数 g.sum()# sum只对数值列求和,非数值列未显示 g.get_group('black')# 指定返回black组数据 g.head(2)# 取每个分组的头2个数据 g.nth(0)# 取每组的第0个数据 g.price.describe()# 对price列做describe,得到一组常用统计量
python
运行
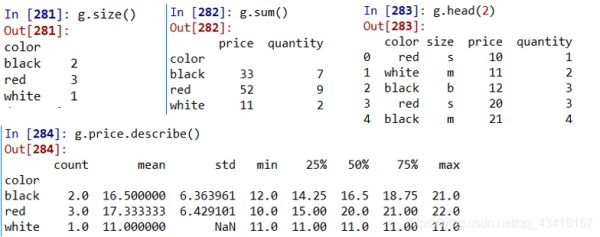
分组对象有一个aggregate合计方法(简写为agg),它允许传递多个统计函数,因此可以一次性得到多个统计值。
# 对quantity列求和、均值、最大值、最小值 g.quantity.agg((np.sum, np.mean, np.max, np.min)) g.quantity.agg([('均值','mean'), ('最大值','max')])# 定义列名
python
运行

练习
m = pd.read_excel('movie.xlsx') # 月度票房前10名 2008-2019 m = m[m.MovieName!='其他'] g = m.groupby(m.month.str[:4]) # 按年分组 2019-01 g.boxoffice.sum()# 按年汇总 票房 g.boxoffice.sum() / m.boxoffice.sum()# 比率 g1 = m.groupby('MovieName')# 按电影名分组 g1.size().sort_values(ascending=False)[:10] # 月度排名出现次数最多,先是按照名字来分组的,然后根据分组后的值来进行排序
python
运行
# 多级索引分组 s = Series(np.arange(5), index=[list('xxyyx'),list('rbrbb')]) g = s.groupby(level=0) # 按0级索引分组 g.size() g.agg(lambda x:(x.max(), x.min()) )# 返回每个分组的最大/最小值
python
运行
数据透视表Excel中有一个数据透视表功能,Pandas提供了类似的命令pivot_table()。
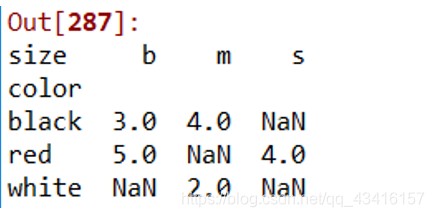
df.pivot_table(index='color', columns='size', values='quantity',aggfunc='sum') color作为行索引,size是列索引,里面的值是quantity,计算方法是sum求和
python
运行
参数表中index指定分组索引列,columns指定列名,values指定要计算的列,aggfunc指定计算方法。例如,'sum’是求和,'mean’是求平均值,'count’是计数。
时间序列
Pandas最初研发的目的是作为金融数据分析包,因此提供了丰富的时间序列处理方法。时间序列做索引,运算时会自动按日期对齐。
Pandas中的时间函数 to_datetime()将字符串转换为时间,识别不同格式的日期字符串。
pd.to_datetime('2019-2-20')# 年-月-日 Out: Timestamp('2019-02-20 00:00:00') pd.to_datetime(['2/20/2019', '2019.2.20']) #不同格式日期字符串都可转换 Out: DatetimeIndex(['2019-02-20', '2019-02-20'], dtype='datetime64[ns]') pd.to_datetime('2019-2-20 15:30:00')# 年-月-日 时:分:秒 Out: Timestamp('2019-02-20 15:30:00') today = pd.datetime.now()# 生成今天的日期 today + pd.DateOffset(days=3)# 后推3天 # 将数据框df的索引类型转为日期型 df = pd.read_csv('stock.txt', index_col=0, encoding='cp936', sep='\s+') df.index = pd.to_datetime(df.index)
python
运行
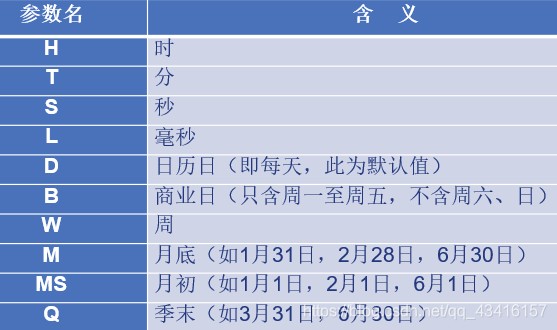
date_range()用于产生指定日期段内的一系列日期时间值。
pd.date_range(起始日期, 结束日期, periods=周期数, freq=日期频率)
date_range函数的常用freq参数表
pd.date_range('2019-02-01', '2019-02-28')# 默认频率1天 pd.date_range('2019-02-01', '2019-02-28', freq='3D')# 频率为每3天 pd.date_range('2019-01-01', periods=6, freq='3D')# 每3天1个日期
python
运行
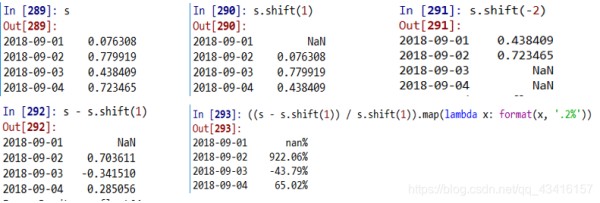
shift()有时需要对日期序列做shift(移动)转换,以计算相邻日期间的数据变动。
np.random.seed(7) dates = pd.date_range('2018-9-1', periods=4) # 生成4个日期索引值 s = Series(np.random.rand(4), index=dates) s.shift(1)# 后移一个数据位 s.shift(-2)# 前移两个数据位 s - s.shift(1) # 计算后一天相对前一天的变动值, s.pct_change() ((s - s.shift(1)) / s.shift(1)).map(lambda x: format(x, '.2%')) # 变动百分比并格式化 s - s.shift(1) 会自动对齐日期索引,完成相同日期的数值相减。
python
运行
用时间作为索引时,可以方便地按时间段查看数据。对时间序列数据可用resample()方法按不同频率进行重采样,然后对样本进行计算。
np.random.seed(7) dates = pd.date_range('2018-1-1', periods=365) s = Series(np.random.randn(365), index=dates) # 2018年模拟数据 s['2018-1']# 选取2018年1月的数据 s['2018-02' : '2018-04']# 选取2018年2月至4月的数据 s.resample("1M").mean() # 按月求均值 s.resample("10D").sum() # 每10天求和 # 每10天一次采样,返回每组样本的最大值、最小值 s.resample("10D").agg([np.max, np.min])
python
运行

练习
股票每日的涨跌幅在区间[-10%, 10%]内,且只在周一到周五交易。 先设置随机数种子为7,试生成模拟一只股票2019年全年交易日的涨跌幅数据。然后计算: (1)该股票2019年的年涨跌幅。 (2)统计12个月中涨幅最大的月份和跌幅最大的月份。
python
运行
import pandas as pd np.random.seed(7) dates = pd.date_range('2019-1-1', '2019-12-31', freq='B')# 全年涨跌数据, B 商业日 df = pd.DataFrame(np.random.uniform(-0.1, 0.1, len(dates)), index=dates,columns=['rate']) for x in ['2019-1-1', '2019-5-1', '2019-10-1']: if x in df.index:# 剔除不交易的节假日 df.drop(pd.to_datetime(x), inplace=True) df['percent'] = df['rate'] + 1 # 加1调整为正值百分比,调整后范围为[0.9, 1.1] yearrate = df['percent'].prod()# 累乘计算全年涨跌幅 print('全年涨跌幅为:{:.2%}'.format(yearrate - 1)) mrate = df.resample('1m')['percent'].prod()# 按月采样 print('全年按月份涨跌幅如下:\n', (mrate - 1).apply(lambda x: format(x, '.2%'))) s = (mrate - 1).sort_values() print('跌幅最大的月份是:', str(s.index[0])[:7]) print('涨幅最大的月份是:', str(s.index[-1])[:7])
python
运行
网址:L:python的Pandas模块:字符串处理,分组统计,数据透视表,时间序列 https://www.yuejiaxmz.com/news/view/1168334
相关内容
Python数据分析——Pandas数据预处理利用Python进行数据分析笔记-时间序列(转换、索引、偏移)
python知识快速补充4——集合,序列(元组,列表,字符串),字典说它们想一起学
python中字符串转数组、数组转字符串
python 字符串列表根据字符串长度排序——lambda、filter、map表达式应用
数据分析逻辑整理——餐厅数据
大数据应用
怎样用spss随机数字表 spss随机数字表法分组
Pandas的时间序列Period,period
【Python数据清洗速成课】:数据结构在有效清洗中的应用
随便看看
最新动态分享
- 十种适合放在室内的绿色植物
- 居家绿色植物有哪些?
- 居家绿植养护:低成本装点家居,治愈现代人的精神内耗
- 这几种绿植最适合放在家里,既能为房间增色还很好养活
- 怎样才能不杀死你的植物 (四季居家绿植的家庭园艺指南)
- 一帆风顺植物的养殖秘籍(打造居家绿色健康生活)
- 适合北方室内养的开花植物?
- 室内居家环境生活绿植盆栽花卉素材图片免费下载
- 家庭常用绿色植物,家庭常用绿色植物知识
- 个人防蚊小贴士(链接)
热点动态分享
- 144956
- 51188
- 44933
- 42324
- 40722
- 30780
- 25424
- 25360
- 21769
- 18469

