强化学习(DDPG,AC3,DPPO)
使用强化学习提高深度强化学习算法的效率 #生活技巧# #学习技巧# #深度学习技巧#
通过把Policy Based 和Value Based结合起来的Actor Critic,解决了Value Based如Q-Learning的无法解决连续和高维度问题,也解决了Policy Based的效率低速度慢的问题。但是同样的,像DQN一样,在使用神经网络进行值估计的时候,神经网络的相关性都太强了,梯度更新相互依赖,导致网络将会学不到东西。
有两种解决方法:DDPG和AC3。
DDPG
Actor-Critic+DQN=Deep Deterministic Policy Gradient。
先将这个词拆成三部分:
Actor-Critic+DQN,两者如何融合?
Actor-Critic:Actor网络学习动作策略,Critic网络用于评价动作。
DQN:记忆库,两套网络解决网络相关性。
DQN中的两套网络是为了计算价值函数,那么还是Value Based,现在加入了Policy Based后,同样也需要两套网络来计算策略函数。即使用双Actor神经网络和双Critic神经网络共有4套网络的方法来改善神经网络更新的收敛性。
对于Actor的双网络 ,有用来估计的新网络和延迟的旧网络。估计网络用来输出实时的动作,而旧网络则是用来更新价值网络系统的.。
对于Critic的双网络,也有估计的新网络和延迟的旧网络。它们都输出根据状态的输出相应的value价值,估计网络根据actor的动作进行输出,而旧网络会根据actor旧网络得到的动作进行输出。
太绕了,于是博主自己画了一张图:
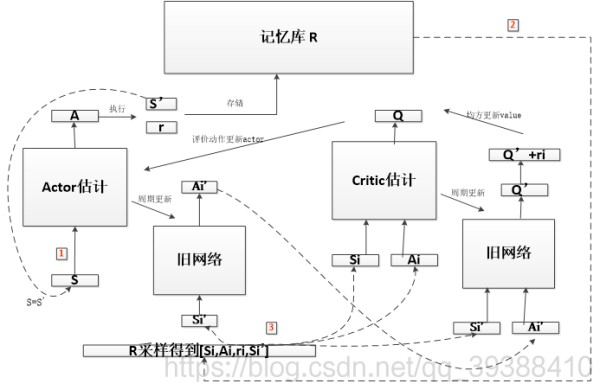
即先从一个状态S出发,通过Actor新网络得到动作A并执行,存入记忆库。然后从记忆库中采样,得到Si,Ai,Si’,Si’通过Actor旧网络得到动作Ai’,用于给Critic更新参数,即输入到Critic旧网络中得到一个“现实目标值”Q’,即可以算出在这个状态下的动作总值y,和Critic的估计值进行均方误差就可以更新Critic网络了。(AC中是用前后V值差的均方来更新,现在使用了旧网络能够更加的客观)而actor的网络用Critic新网络得到的Q值来评价动作的好坏,即就用来更新了Actor网络。(AC中是用Reward的TD误差来更新,现在通过旧网络同样更客观了)
Critic 参数更新公式为:
L = 1 N ∑ i ( y i − Q ( s i , a i ∣ θ Q ) ) 2 L=\frac{1}{N}\sum_i(y_i-Q(s_i,a_i|\theta^Q))^2 L=N1i∑(yi−Q(si,ai∣θQ)
网址:强化学习(DDPG,AC3,DPPO) https://www.yuejiaxmz.com/news/view/1283023
相关内容
基于强化学习的智能家居能源管理强化学习下的无人驾驶决策技术
强化学习之确定性策略网络和随机策略网络
基于强化学习的保存策略优化
基于强化学习的综合能源系统管理综述
强化学习系列
强化学习
能源系统优化?尝试下强化学习:基于强化学习(Python
深度强化学习算法的样本效率(sample efficiency)到底是什么?
一文了解强化学习
随便看看
最新动态分享
- 家庭消毒不用愁!5大物理消毒法守护健康生活
- カビをアルコール退治|消毒用エタノールでの除菌方法やNG使用法も
- 消毒产品目录
- 基于STM32的智能鞋柜控制系统设计与实现
- 【解決】家具に生えたカビの取り方、予防法、原因を紹介
- 抗菌实验不同操作方法及细节对试验结果的影响
- 多部门推动物联网创新发展 到2028年这些技术要突破
- 生活区节水节电节能管控措施.docx
- 家庭节约用电有哪些具体方法?
- 北京市出台碳普惠管理办法 市民低碳行为将能“变现”
热点动态分享
- 145110
- 52410
- 45122
- 42498
- 40934
- 30915
- 25710
- 25536
- 21924
- 18630

