能源系统优化?尝试下强化学习:基于强化学习(Python
尝试个性化学习路径推荐系统 #生活乐趣# #创新乐趣# #趣味学习工具#
最近一直在做机器学习和能源系统优化相关的前期学习,根据以前导师的推荐,尝试强化学习方法在能源调度优化中的应用,一些简单的测试分享给大家,如果有大佬有改进或其他建议欢迎交流。
1. 背景介绍
在能源系统中,面对多样化的能源需求(如电力、热力、冷需求)和不确定的可再生能源供应(如风电、光伏),如何实现能源的高效调度成为一个重要问题。多能系统的调度优化需要在以下目标之间进行权衡:
满足能源需求:保证电力、热力和冷需求的实时供应。优化储能设备使用:合理利用储能设备(如电池)进行充放电。碳捕集与成本控制:在满足低碳目标的同时,降低碳捕集设备的运行成本。传统方法往往基于线性规划或动态规划,难以应对系统的非线性、不确定性和高维特性。强化学习(Reinforcement Learning, RL) 提供了一种新思路,通过智能体与环境的交互,不断优化策略,动态适应复杂的能源调度场景。 模型框架本文采用 Soft Actor-Critic (SAC) 算法,结合 Gym 环境自定义了一个多能系统的调度优化模型,主要由以下几个部分构成: 2.1 状态空间
状态空间用于描述当前多能系统的运行状态,本文设计了 6 个状态变量:
电力需求(Power Demand)
热需求(Heat Demand)
冷需求(Cooling Demand)
储能状态(SOC, State of Charge)
风电输出(Wind Power)
光伏输出(PV Power)
这些状态变量的取值范围被归一化到 [0,1]
2.2 动作空间
动作空间表示智能体可以采取的控制动作,包括:
储能充放电功率(Storage Power):取值范围 [−1,1],正值表示充电,负值表示放电。
碳捕集设备加载率(Carbon Capture Rate):取值范围 [0,1],表示碳捕集设备的运行负荷率。
奖励函数用于评估每一步智能体动作的优劣,包含两个部分:
能量平衡奖励R b a l a n c e = − m a x ( 0 , 需求总量 − 供应总量 ) R_{balance} = -max(0, 需求总量 - 供应总量) Rbalance=−max(0,需求总量−供应总量)
碳捕集成本奖励R c a r b o n = − 0.1 ∗ 碳捕集率 R_{carbon} = -0.1 * 碳捕集率 Rcarbon=−0.1∗碳捕集率
总奖励函数R = R b a l a n c e + R c a r b o n R = R_{balance} + R_{carbon} R=Rbalance+Rcarbon
2.4 学习目标智能体通过 SAC 算法学习一个最优策略 (\pi(a|s)),以最大化累积奖励:
G t = Σ ( γ k ∗ R ( s t + k , a t + k ) ) G_t = Σ (γ^k * R(s_{t+k}, a_{t+k})) Gt=Σ(γk∗R(st+k,at+k))
其中:
(G_t):从当前时间步 (t) 开始的累计折扣奖励;(γ):折扣因子,用于权衡短期和长期奖励,取值范围 ([0, 1])。 环境更新公式 储能状态更新S O C = c l i p ( S O C + S t o r a g e P o w e r ∗ 0.05 , 0 , 1 ) SOC = clip(SOC + Storage Power * 0.05, 0, 1) SOC=clip(SOC+StoragePower∗0.05,0,1)
其中:
(SOC):储能设备的状态,范围为 ([0, 1]);(Storage Power):储能的充放电功率;(clip):限制范围在 ([0, 1])。3. 模型工作流程
模型的整体流程如下:
初始化环境:定义状态空间、动作空间和初始状态。智能体交互:
智能体根据策略网络 (Π(a|s)) 输出动作,与环境交互并获取新的状态和奖励。奖励计算:
根据智能体的行为,环境计算奖励,智能体用此信息优化策略。终止条件:
当时间步达到 200 或其他终止条件时,回合结束,重新初始化环境。
在stable_baselines3中我们创建的SAC框架下,默认采用MLP作为神经网络(且奖励网络
源代码测试库环境是否正确,测试在python3.9.20环境中完成
import gym import stable_baselines3 import optuna import numpy print(gym.__version__) print(stable_baselines3.__version__) print(optuna.__version__) print(numpy.__version__)
python
运行
12345678910输出如下:
0.26.2 2.4.0 4.1.0 1.26.4 e:\Pythonworkshop\DRL_work\.conda\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
bash
1234567项目测试代码:
import numpy as np import gym from gym import spaces from stable_baselines3 import SAC from stable_baselines3.common.vec_env import DummyVecEnv from stable_baselines3.common.callbacks import EvalCallback import optuna class MultiEnergySystemEnv(gym.Env): def __init__(self): super(MultiEnergySystemEnv, self).__init__() # 状态空间:电力需求、热需求、冷需求、储能SOC、风电、光伏 self.observation_space = spaces.Box(low=0, high=1, shape=(6,), dtype=np.float32) # 动作空间:储能充放电功率[-1, 1],碳捕集设备加载率[0, 1] self.action_space = spaces.Box(low=np.array([-1, 0]), high=np.array([1, 1]), dtype=np.float32) # 初始化状态 self.state = self.reset() self.timestep = 0 def reset(self): # 初始化状态 self.timestep = 0 self.state = np.random.uniform(0, 1, size=(6,)) return self.state def step(self, action): """ 动作的执行: - action[0]: 储能充放电功率(-1到1),这里假设功率是可以直接调节的,而且没设置上下限 - action[1]: 碳捕集设备加载率(0到1),同理。 """ power_demand, heat_demand, cooling_demand, soc, wind_power, pv_power = self.state storage_power = action[0] carbon_capture_rate = action[1] # 更新储能状态 soc = np.clip(soc + storage_power * 0.05, 0, 1) # 奖励函数: # 1. 满足需求的程度(正向奖励),因为是随机的数据,所以采用简单的正向奖励,满足需求的程度越高,奖励越高,没满足就是负值奖励 renewable_supply = wind_power + pv_power + storage_power unmet_demand = max(0, power_demand + heat_demand + cooling_demand - renewable_supply) energy_balance_penalty = -unmet_demand # 2. 碳捕集成本(负向奖励),碳捕捉的开启量越多,成本越高,是一个负向奖励,但是我们要实现碳捕捉达到碳平衡,所以需要衡量。 carbon_capture_cost = -0.1 * carbon_capture_rate # 总奖励 reward = energy_balance_penalty + carbon_capture_cost # 更新状态 self.state = np.random.uniform(0, 1, size=(6,)) self.state[3] = soc # 保留SOC状态 self.timestep += 1 # 结束条件 done = self.timestep >= 200 return self.state, reward, done, {} def render(self, mode='human'): pass # 创建环境 env = DummyVecEnv([lambda: MultiEnergySystemEnv()]) # 使用Optuna优化超参数 def optimize_sac(trial): # 超参数搜索空间 learning_rate = trial.suggest_loguniform('learning_rate', 1e-4, 1e-2) batch_size = trial.suggest_categorical('batch_size', [64, 128, 256]) gamma = trial.suggest_uniform('gamma', 0.9, 0.99) # 初始化模型 model = SAC("MlpPolicy", env, learning_rate=learning_rate, batch_size=batch_size, gamma=gamma, verbose=0) # 定义评估回调 eval_callback = EvalCallback(env, eval_freq=500, n_eval_episodes=5, deterministic=True, verbose=0) # 训练模型 model.learn(total_timesteps=5000, callback=eval_callback) # 返回评估奖励 return eval_callback.last_mean_reward # 使用Optuna调优超参数 study = optuna.create_study(direction='maximize') study.optimize(optimize_sac, n_trials=10) # 获取最佳超参数 best_params = study.best_params print("Best Hyperparameters:", best_params) # # 使用最佳超参数训练最终模型 final_model = SAC("MlpPolicy", env, learning_rate=best_params['learning_rate'], batch_size=best_params['batch_size'], gamma=best_params['gamma'], verbose=1) final_model.learn(total_timesteps=10000) # 测试模型 # obs = env.reset() # for _ in range(200): # action, _states = final_model.predict(obs, deterministic=True) # obs, reward, done, info = env.step(action) # if done: # break
python
运行
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108输出如下,这里注释可以在简单测试中直接输出(我这里注释掉是因为后续还有可视化代码,我挪到了后面的代码中。
[I 2024-11-26 15:12:57,728] Trial 1 finished with value: -24.918968804553153 and parameters: {'learning_rate': 0.0005655815624737378, 'batch_size': 128, 'gamma': 0.9662472727755294}. Best is trial 1 with value: -24.918968804553153. [I 2024-11-26 15:14:10,829] Trial 2 finished with value: -50.52137580886483 and parameters: {'learning_rate': 0.00014604497098531745, 'batch_size': 64, 'gamma': 0.9032240575945991}. Best is trial 1 with value: -24.918968804553153. [I 2024-11-26 15:15:24,957] Trial 3 finished with value: -25.443975274125116 and parameters: {'learning_rate': 0.0037060046463788833, 'batch_size': 256, 'gamma': 0.9818166794679356}. Best is trial 1 with value: -24.918968804553153. [I 2024-11-26 15:16:39,040] Trial 4 finished with value: -21.29798140048515 and parameters: {'learning_rate': 0.007417257237361141, 'batch_size': 64, 'gamma': 0.9255433805615282}. Best is trial 4 with value: -21.29798140048515. [I 2024-11-26 15:17:54,145] Trial 5 finished with value: -23.787771976180373 and parameters: {'learning_rate': 0.0008033039100736049, 'batch_size': 64, 'gamma': 0.9048781993641628}. Best is trial 4 with value: -21.29798140048515. [I 2024-11-26 15:19:05,608] Trial 6 finished with value: -24.925974791962652 and parameters: {'learning_rate': 0.0014261015828433456, 'batch_size': 256, 'gamma': 0.9170627412247911}. Best is trial 4 with value: -21.29798140048515. [I 2024-11-26 15:20:13,904] Trial 7 finished with value: -42.311299515515564 and parameters: {'learning_rate': 0.0002078766135331994, 'batch_size': 256, 'gamma': 0.935028694164879}. Best is trial 4 with value: -21.29798140048515. [I 2024-11-26 15:21:23,830] Trial 8 finished with value: -23.916750478430185 and parameters: {'learning_rate': 0.002963057386666943, 'batch_size': 128, 'gamma': 0.9080140367653581}. Best is trial 4 with value: -21.29798140048515. [I 2024-11-26 15:22:35,843] Trial 9 finished with value: -19.814121935679577 and parameters: {'learning_rate': 0.0008142906301786324, 'batch_size': 64, 'gamma': 0.9677305642804671}. Best is trial 9 with value: -19.814121935679577. Best Hyperparameters: {'learning_rate': 0.0008142906301786324, 'batch_size': 64, 'gamma': 0.9677305642804671} Using cuda device --------------------------------- | time/ | | | episodes | 4 | | fps | 91 | | time_elapsed | 8 | | total_timesteps | 800 | | train/ | | | actor_loss | -1.9 | | critic_loss | 0.137 | | ent_coef | 0.57 | | ent_coef_loss | -1.73 | | learning_rate | 0.000814 | | n_updates | 699 | --------------------------------- 过多,后续省略
bash
1234567891011121314151617181920212223242526可视化代码如下:
import numpy as np import matplotlib.pyplot as plt obs = env.reset() # 初始化存储变量 rewards = [] actions = [] states = [] # 测试模型 for _ in range(200): action, _states = final_model.predict(obs, deterministic=True) obs, reward, done, info = env.step(action) actions.append(action.reshape(-1)) rewards.append(reward) states.append(obs.reshape(-1)) if done: break actions = np.array(actions) states = np.array(states) if len(states.shape) == 1: states = states.reshape(-1, 1) rewards = np.array(rewards) # 奖励趋势 plt.figure(figsize=(10, 6)) plt.plot(rewards, label="Reward per Step") plt.title("Reward Over Time") plt.xlabel("Time Step") plt.ylabel("Reward") plt.legend() plt.grid() plt.show() # 动作变化趋势 plt.figure(figsize=(10, 6)) plt.plot(actions[:, 0], label="Storage Power (Action 0)") if actions.shape[1] > 1: # 如果有多个动作 plt.plot(actions[:, 1], label="Carbon Capture Rate (Action 1)") plt.title("Actions Over Time") plt.xlabel("Time Step") plt.ylabel("Action Value") plt.legend() plt.grid() plt.show() #关键状态变量 plt.figure(figsize=(10, 6)) # 如果状态空间有多维,可以绘制储能状态 (SOC) if states.shape[1] > 3: # 确保第 4 列 (索引为 3) 存在 plt.plot(states[:, 3], label="SOC (State 3)") # 绘制储能设备状态 (SOC) else: print("State dimension too small, cannot plot SOC.") plt.title("State Changes Over Time") plt.xlabel("Time Step") plt.ylabel("State Value") plt.legend() plt.grid() plt.show() # 平滑奖励趋势 def moving_average(data, window_size): data = np.array(data).flatten() return np.convolve(data, np.ones(window_size) / window_size, mode='valid') # 平滑奖励曲线 rewards = np.array(rewards).flatten() plt.figure(figsize=(10, 6)) plt.plot(moving_average(rewards, window_size=10), label="Smoothed Reward") plt.title("Smoothed Reward Over Time") plt.xlabel("Time Step") plt.ylabel("Smoothed Reward") plt.legend() plt.grid() plt.show()
python
运行
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879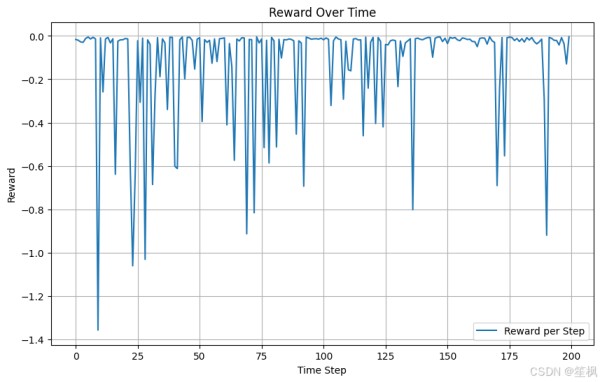
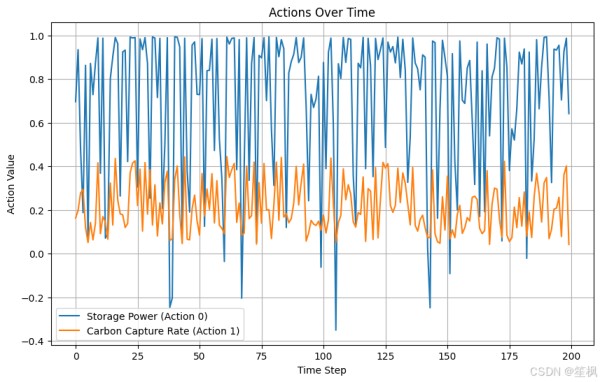
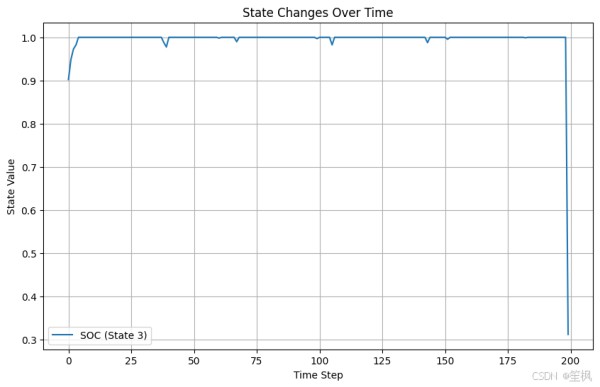
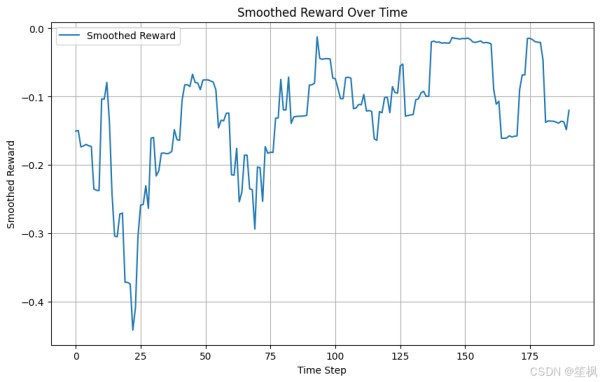
在本次测试当中,以测试项目是否具有可行性、代码是否可以跑通为主,对结果的正确性不做保证,目前来看在随机生成的数据中,强化学习的代理模型仍能够尽可能像最大化奖励运行,初步验证可行。
相比优化求解器来确定我们能源调度的最优解,利用强化学习可能带来的优点如下:
动态适应性强:适合处理不确定性和动态变化的复杂环境。无需显式建模:避免复杂数学建模,适配高维非线性问题。实时性强:训练后推理速度快,适合实时调度和控制。网址:能源系统优化?尝试下强化学习:基于强化学习(Python https://www.yuejiaxmz.com/news/view/953686
相关内容
基于强化学习的综合能源系统管理综述基于强化学习的智能家居能源管理
基于深度强化学习的新型电力系统调度优化方法综述
创建高性能强化学习环境:关键技术与优化策略
基于知识图谱的个性化学习资源推荐系统的设计与实现(论文+源码)
基于Python算法优化:智能衣柜管理系统设计与实现
强化学习与优化的区别与结合
一文了解强化学习
一种基于深度学习的无线网络资源优化系统及方法
强化学习系列
随便看看
最新动态分享
- 任职知名大厂、年薪超50万仍想“多赚钱改善生活”,3名研究生兼职当黑客被抓
- 在女性黑客松上,看见AI硬件的另一种可能
- 境外黑客制作假页面窃取敏感数据
- 安联人寿遭黑客攻击,客户信息被泄露
- 某企员工用搜索引擎下载软件 不慎落入境外黑客窃密陷阱
- 亚马逊报告:黑客利用AI工具五周内攻破全球超600个防火墙
- 从0到1孵化AI创意,黑客松顶尖高校联赛落下帷幕
- 一场黑客松背后,上海正形成更多AI创业“连接器”
- 工作模拟游戏推荐哪个 最新工作模拟游戏精选
- 黑客游戏哪个最好玩 十大必玩黑客游戏排行榜
热点动态分享
- 143819
- 44416
- 44004
- 39586
- 37263
- 29007
- 24204
- 24052
- 20352
- 17569

