大数据清洗随手记(一)
基于Python的大数据清洗
引言
大数据可能是2017年之后最火的一个题材了。与其说是题材,我倒感觉可以理解为食材,一个只需要添油加火就炒热的食材。作为一个JavaWEB的开发人员,我曾特别“瞧不上”大数据,认为大数据并不是一个谁都可以做得来的东西,也不是一个我这样Java开发小白能承受得来的东西。但是“老天爷”就是喜欢和你看玩笑,你越不愿意接触的东西,他就会强硬地让你接触,我们公司迎来了战略发展转型期,而大数据就是其中的一个发展方向,很“幸运”我被分配到了大数据研发小组,开始了我战争般的职业生涯。闲话不多说正文开始:
简介
大数据:超过TB,EB级的数据信息
Python:一门高级(任性编写)的开发语言
那么问题来了,大数据清洗为什么要用Python呢?答:因为import!!!Python提供了数不尽的依赖库,Pandas、numpy、matplotlib等等,这些前人的智慧促使了我们使用Python语言进行大数据清洗,Python提供很多的算法分析来进一步的帮助我们进行数据分析和清理。
正文
Pandas实现读取不同的数据源文件:import pandas as pd
import cx_Oracle
import os
from _operator import index
读取csv文件的方法:
xls = pd.read_excel('D:/RData/demo/1234.xlsx')
读取Excel文件的方法:
注意这里是office的Excel文件,WPS可能会报错。
data = pd.read_csv("D:/RData/demo/123.csv")
读取Oracle数据库的方法:
os.environ['NLS_LANG']='SIMPLIFIED CHINESE_CHINA.ZHS16GBK'
host = "127.0.0.1"
port = "1521"
sid = "DAXON"
dsn = cx_Oracle.makedsn(host, port, sid)
conn = cx_Oracle.connect("WMIS", "root", dsn)
sql = 'SELECT RACID,RAADDR,RAREADER,RABUSSID,RABUSSDATE,RAUSENUM,RAPRICE,RAREADMONTH FROM WMIS_REC_ACC'
result = pd.read_sql(sql,conn)
conn.close
读取后的数据存到了dataframe中,方便进行数据清洗操作。以下的方法中还有许多参数,请自行参考API
基于Python的数据清洗数据去重(和按指定字段去重):
result_noDup = result.drop_duplicates()
data_drop=result.drop_duplicates(['ID'])
数据去空(慎用):
result_noNull = result_noDup.dropna()
打印数据描述,判断异常值。(这里只会统计整数值)
print(result_noNull.describe())
图形结果如下:
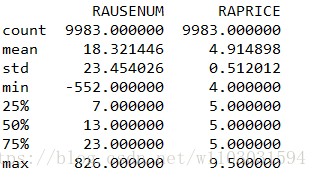
根据业务可以选择清除最大值和最小值:
result=result_noNull.drop((result_noNull[result_noNull['RAUSENUM'] < 0]).index.tolist())
result = result.drop((result[result['RAUSENUM']==826]).index.tolist())
print(result.describe())
数据替换:
当数据样本量小的时候,删除数据是不可取的,这会影响到数据的分析建模。所以我们采用数据的平均数,众数或中位数替换的方法读数据进行清洗。众数、平均数、众数可以通过遍历字段求取,这里就不做展示了
result['RAUSENUM']=result['RAUSENUM'].replace([1,2,3],np.nan)
result['RAPRICE']=result['RAPRICE'].replace(0,1)
result_rep=result
具体数据类型化:
当业务需求对数据的取值范围进行统计,将一定范围的数据定义为以一个类形时,这时我们就需要对数据一定范围内数据进行具体类型化。
cutPoint=[0,1000,3000,6000,10000]
result_rep['RAUSENUM']=pd.cut(result_rep['RAUSENUM'],cutPoint)
print(result_rep)
groupLable=['1','2','3','4']
result_rep['CutUseNum']=pd.cut(result_rep['RAUSENUM'],cutPoint,labels=groupLable)
print(result_rep)
根据正则表达式清洗:
正则表达式是一种十分规范的数据清洗方式,我们可以通过定义正则表达式匹配字段每一行的值,从而抛弃掉那些不符合正则的数据。
for row in result_noNull.index:
pattern=result_noNull.loc[row].values[1]
if(not(re.search(r'^[\u4e00-\u9fa5]{1,8}$', pattern))):
result_noNull.drop(row)

分别按照年度、季度、月度进行统计:
result['RABUSSDATE'] = pd.to_datetime(result['RABUSSDATE'])
result1=result.set_index('RABUSSDATE')
result_year=result1.resample('AS').sum().to_period('A')
result_year=result1.resample('Q').sum().to_period('Q')
result_year=result1.resample('M').sum().to_period('M')
print(result_year)
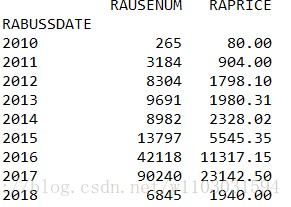
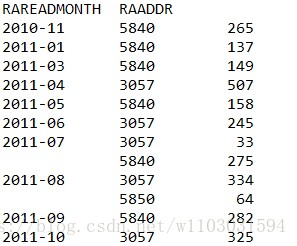
根据双重条件进行数据统计:
result_gb=result['RAUSENUM'].groupby([result['RAREADMONTH'],result['RAADDR']]).sum()
print(result_gb)
网址:大数据清洗随手记(一) https://www.yuejiaxmz.com/news/view/21605
相关内容
日常生活中的数据清洗:提升生活品质的隐形环节【Matlab学习手记】BP神经网络数据预测
家庭清洁九大小妙招,随手就可以做
《2023中国健身行业数据报告》正式发布!首次公布健身会员体测数据
三大生活技能数据分析!
Pandas 数据处理(一)缺失值处理
时空数据:为智慧生活注入新活力
【Java数据结构】字符串常量池
EXCEL函数及数据分析技巧整理备用
有了这个整理法,数据线再也不烦人了!
随便看看
最新动态分享
- 家庭消毒不用愁!5大物理消毒法守护健康生活
- カビをアルコール退治|消毒用エタノールでの除菌方法やNG使用法も
- 消毒产品目录
- 基于STM32的智能鞋柜控制系统设计与实现
- 【解決】家具に生えたカビの取り方、予防法、原因を紹介
- 抗菌实验不同操作方法及细节对试验结果的影响
- 多部门推动物联网创新发展 到2028年这些技术要突破
- 生活区节水节电节能管控措施.docx
- 家庭节约用电有哪些具体方法?
- 北京市出台碳普惠管理办法 市民低碳行为将能“变现”
热点动态分享
- 145116
- 52515
- 45139
- 42504
- 40948
- 30923
- 25724
- 25538
- 21931
- 18652

