法学生个人Deepseek使用技巧指北
使用自然指南针:利用磁石和指北针,找到北方 #生活技巧# #紧急应对技巧# #野外求生技能#

来源 | Rosenberg星期四自留地
为什么会想起来小写一篇呢,是因为随着近日DeepSeek-R1这个现象级国产AI大模型的爆火,法学领域也涌现出了很多关于如何使用DeepSeek的内容,有知名教授的,有业界大牛律师的,也有各地法院的。从法律信息检索、立法修法对比、案例分析、文章润色、文献综述到诉讼策略制定,各种法学用途都在被开发。这是ChatGPT独秀的时代比拟不了的法学AI热情。
但是,读了多个社媒平台已有的内容,我感觉某些法学内容是不太适合用AI输出的;部分用途虽然言之有理,但却比较粗糙,很难起到提高工作效率的作用,甚至会因为典型的“AI谎言”陷入反效果。
作为法学文科生,我们对于大语言模型原理的理解是拍马难及CS领域的专业人士的,这属于有一定门槛的知识。但是,我们在自己的专业领域内探索所谓AI用途前,应当去尽力迈过这个门槛。当然,鄙人才疏学浅,不敢妄议全体法律人,因此本文的标题是法学生的DeepSeek使用指北,请法学生尽情食用随意批评,请工科专业的童鞋和专家无需食用尽情批评。
我很早就开始在日常学业和个人知识管理中使用AI工具了,但法学相关的其实一直控制在有限的内容框架下,不是没有尝试过扩大,而是逐渐在学习AI原理与实操过程中发现,只有精致化、类型化工作学习场景,AI才能给我的效率带来正的边际收益。学术润色(尤其英文)、文献翻译、文献总结、知识整理是我经常使用的场景。在DeepSeek-R1上线后,我也做了不少尝试,确实在中文法学语境下的表现非相比同行常的出色,用途可以进行一定程度的扩展。
不过,时间有限,今天就只写一些些内容啦,我要去背单词qwq。
I. 不应当将DeepSeek用作法律检索的搜索引擎!!!
在大部分文章中,都会把“法律信息检索”作为DeepSeek的重要功能。 但我的观点只有一个,不推荐也不应当将DeepSeek及任何其他野生大语言模型作为搜索引擎使用,在法律信息专业检索上尤其如是。
“AI真的好聪明”“他能像人一样跟我对话”“他能联网进行检索”“我平常的搜索引擎多么难用”“法律数据库还要登录”“裁判文书网更是xxxx”。以上想法很容易得出一个结论:我们让聪明的DeepSeek帮我做检索,一定能够省很多力气,得出比我自己做几个小时法律检索更全面的结论吧!但这件事情至少在法学领域是黄粱一梦,而且是刚好踩在原理危险边缘的美梦,这是老生常谈的话题——准确性风险。
说到这儿反驳者一定众多,DeepSeek作为国产大模型中文能力这么强,都能写小说写散文写批评文学甚至写公众号了,看不起谁呢?但是恰恰这是两码事儿,要理解这件事儿,我们需要简单理解一下大语言模型是以什么样的方式在与我们“对话”的,只用法学领域的通俗语言解释。(关于AI原理的内容呀,有很多我会向我的多年好友、现B站著名科普UP主“漫士沉思录”学习,去年因为一直包着油管的pre,所以也经常刷着学习一些英文资源。当然还是才疏学浅,请尽情批评指正)
1. 统计语言模型与自回归生成
在与DeepSeek进行对话的时候,我们会发现他的回答是像PPT的流水特效那样一个字一个字地展开的,这其实不仅仅是一种视觉UI,也是他思考和回答你的方式,他真的是现代曹植,走一步说一步。
大语言模型是通过前文的内容来预测下一个字儿应当、大概率、更可能是什么,然后将这个答案输出给你的,这是统计语言模型(Statistical Language Model)大概的意思。同时,DeepSeek不断地将自己已经输出的文本内容也纳入到条件中来,使之同样成为下一个字儿预测的语料,这是自回归生成。当然,说“一个一个字儿”是不准确的,容后再议。
说到这里,聪明的你一定想到法律领域的检索究竟踩中了什么风险点了。在GPT刚开始被使用的时候,很多律师、法学生都会对其诟病,因为他说谎,他会输出一条根本不存在的法条、一个根本不存在的虚空法案、一个根本不存在的西北风案号给你,并且装得煞有其事,让很多人轻信了他天真的双眸,将结果用在了论文、memo、法律文件里,最终饮恨西北。GPT会撒谎!那个时候大家都会这么说。但是流着中国血的DeepSeek会克服吗?
不会,因为他也是大语言模型。我们日常的法律检索,法条、法案、案号都特别重要,大部分法学生随手就能写出一个案号的结构,最高人民法院(2024)民申字第189号。当然这个案号是不一定存在的,但是他符合语义逻辑,和各种各样法律领域语料中他的千千万万的孪生兄弟们长得非常相似。那么DeepSeek会怎么想呢,当他需要在这个节点给你一个案例的时候,他的统计语言模型和自回归生成的原理会带来什么?
和我现在一样,输出一个看起来很对的案号,生成一个看起来很对的法案名称,完全没有负担,非常符合逻辑。而你,会去检验吗?或许吧,大家自己知道。
2. DeepSeek看到的世界和我们是相同的吗?
我们刚才说到,DeepSeek会预测下一个“字儿”是什么,这么说不太准确,因为DeepSeek作为一个大语言模型,他在被训练的时候,看到的、理解的、希冀的世界,与我们自然人是不同的。我们自然人,日常生活中说话,或者学习一门语言,都是自然语言,我们的思维模式是,想要表达一个意思,然后用我们已有的语法结构去构建这样一个足以表达内心的文本。就好像我学日语一样,当我看到美丽的大海,需要用二类形容词 綺麗 修饰大海的时候,我会加上一个助词な,因为我学过日语语法和这些单词。
DeepSeek怎么了解到这一点的呢,他在训练材料里面找到了这些内容的关联性,日语里綺麗这个词经常跟着な,很多文本都这样,怎么会这样呢?原来后面经常有大海、天空、建筑、星光。那么他的训练是和我们一样在理解词汇、学习语法结构吗?不是,是我们人为地将这些有关联性地文本转化成为了“token”或者说语素喂给他,他从无数这些token的关联性中把握到了这些规律。所以,DeepSeek从被训练开始,他眼里的世界与我们自然人,是不同的,他对语言的把握本质上是一种最为高级的鹦鹉学舌,而不是你所想象的和你对话的中文日语德语英语能力都点满技能点的一个人。他预先经过了训练(Pre-Trained),也懂得把token换算成汉字,换算成德语的derdiedas,换算成日语的助词动词,一步步地预测下一个token是什么,生成(Generate)他,转换(Transfom)他,这叫Generative Pre-Trained Transfomer。
那么这个时候聪明的你又已经想到用DeepSeek做法律检索会有什么问题了。法律语言,或者说我们法学院经常训练的法言法语,本质上是一种更为高阶的专业领域的自然语言,AI有没有掌握到足够完美呢?你心里会有答案的,自然语言的prompt,尤其是法律语言,这是你输入给他的内容,也是你看到的世界。但他可能无法无损耗地被转换成DeepSeek眼中的世界里的token。造成的后果,就是信息的反馈被吞掉了。
同样使用自然语言的中国人和日本人,交流之间尚无法理解今夜月色綺麗的美好,那么与DeepSeek交流的时候,你是否想过他眼中的世界是怎样映射你的言语的呢?
3. 注意联网检索和数据库问题
这个其实大家都懂,不再赘述了,DeepSeek的训练数据是截至2023年的,所以大家如果没有点击联网检索的开关,2024年的信息是获取不到的,同时,DeepSeek的训练数据可能并不包含我们日常习得的法律检索技能中常用的那些数据库。而且,DeepSeek的联网检索可能也并不包含微信公众号的内容检索,懂的都懂。
4. 一个可能的方案
如果非要将DeepSeek作为法律检索的搜索引擎,你需要进行一些“调教”,当然我个人感觉效率还没有我自己做法律检索来得高。
例如,我会先让他生成一份检索方案:

他的输出结果是这样的:

然后我会根据特定的需要,在里面选取一些途径让他做检索,或者这份检索报告本身就已经能够给你自己的实操提供比较好的思路了。
并且,在进行检索报告生成时,你的检索内容要尽可能细节,提供给他足够的“背景“和”要求“,什么按照法律要件归纳代位权问题,什么检索代位权相关案例,都太笼统了。当我以一个法学研究者的身份明确要求他在债权人代位权的议题下对于日本、德国、法国、英国、美国及其他国家与地区进行比较法的归纳与总结时,他生成的答案还是可以看的,不过可能仅限于对这个问题了解不深的情况。

II. DeepSeek的应用场景:知识管理案例篇
迫于时间所限,今天只能在第一篇介绍一个我个人可以做得比较精细化的法学领域应用场景啦,那就是案例的管理。当然,很多现有材料都已经提出了可以让DeepSeek做案例分析,例如以请求权基础的结构进行分析等等。但我对于他请求权分析能力的信任感确实还是没有完全建立起来,我试了一两个案例,整体形式还是不错的,有待探索。
个人比较成熟的案例处理模式是,我会做好一个Markdown语句写就的案例报告模板,包括案号、法院、当事人、诉讼请求、程序进程、争议焦点、请求-抗辩体系、分点判决理由、判决主文等内容,然后通过上传附件的方式让DeepSeek根据这一模板输出Markdown语法的案例分析报告,将这一报告导入到我的Notion数据库以及其他可以使用Markdown语法的软件中,就是一篇成形的可以纳入知识管理收藏的案例文本啦。免去了不少读案例的苦恼。他还给我私自生成了一段请求-抗辩-再抗辩的逻辑mermaid,我看着还是有点意思的。

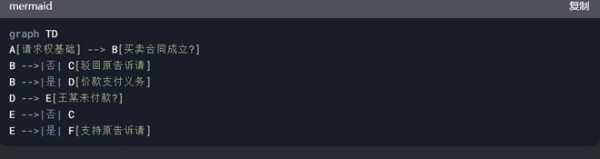
这样的思路是可迁移的,下一个应用场景就是DeepSeek帮我们读一篇论文之后,输出一个关于这篇论文核心观点的Markdown模板下的Note,然后我们可以直接将其与Zotero软件中的论文笔记模板同步匹配,实现不需要精读的论文的浏览和摘要。当然,这可能需要zotero一些插件和设置的配合与调教,我们可以今后再说。
III. 小结
或许很多时候,崇拜与轻蔑同根同源,都只是伊卡洛斯翅膀上的蜡层,不去靠近,不去燃烧,不去触碰本质,就只会生活在自我与他我认知的迷雾里。AI这个东西,在法学界变成普罗米修斯的火种,还是变成法厄同驾驶的太阳战车,看的不是Title,不是赛博热情,而是凡人能不能跨出自己的领地去用智识探索对方眼底的世界。
我模仿DeepSeek的赛博希腊文风写的,哦你问啥是赛博希腊文风,是我和他聊文学创作聊出来的,over。
法宝新AI系列产品
智能写作
智能问答
模拟法庭
法宝来合同
法宝合规
责任编辑 | 吴晓婧
审核人员 | 张文硕
本文声明 | 本文章仅限学习交流使用,如遇侵权,我们会及时删除。本文章不代表北大法律信息网(北大法宝)和北京北大英华科技有限公司的法律意见或对相关法规/案件/事件等的解读。
网址:法学生个人Deepseek使用技巧指北 https://www.yuejiaxmz.com/news/view/934515
相关内容
法学生个人Deepseek使用技巧指北DeepSeek 全面指南,90% 的人都不知道的使用技巧
DeepSeek全面指南:90%的人都不知道的使用技巧(建议收藏)
全网最全的DeepSeek使用指南,99%的人都不知道的使用技巧
北京大学发布第二份DeepSeek教程:实用技巧助你提升AI应用效率!
DeepSeek使用指南:提升效率的七大提示词技巧
北京大学发布第二份DeepSeek教程:全面提升AI使用效率
教师必看!DeepSeek超全使用指南
DeepSeek实用技巧系列
省心省力的AI助手:DeepSeek超简单使用指南
随便看看
最新动态分享
- 适合搭配的食材
- 食疗养生大全:67种天然食材搭配与食疗方,吃出健康好气色
- 哪些食材可以搭配食用 十对最佳食材搭配好吃又健康
- 壮阳补肾煲汤大全:中药配方与食材搭配全解析
- 广东鱼肚汤的家常做法大全|营养功效+食材搭配+5种经典汤谱(附详细步骤)
- 四季美容养颜豆浆配方大全|天然食材搭配+科学原理,喝出透亮肌
- 零失败家常小炒菜谱大全(附新手必学技巧+食材搭配指南)
- 补肾食谱大全:10种家常食疗方+食材清单,科学搭配提升肾动力
- 5种营养搭配!家常鸡汤快手做法大全(附不同做法+食材禁忌)
- 麻辣香锅食材菜单大全图
热点动态分享
- 144597
- 47768
- 44624
- 40401
- 40292
- 30623
- 25135
- 25006
- 21606
- 18303

