 于 2020-03-06 01:14:27 发布 · 1.5k 阅读
于 2020-03-06 01:14:27 发布 · 1.5k 阅读* 项目工作流程
基本流程:
数据清洗与格式转换 探索性数据分析 特征工程 建立基础模型,尝试多种算法 模型调参 评估与测试 解释我们的模型 完成项目一. 数据清洗与格式转换
import warnings warning.filterwarnings('ignore') import pandas as pd import numpy as np pd.set_option('display.max_columns', 60) pd.options.mode.chained_assignment = None # No warnings about setting value on copy of slice import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.size'] = 24 from IPython.core.pylabtools import figsize import seaborn as sns sns.set(font_scale = 2) data = pd.read_csv('Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv') data.head()
python
运行
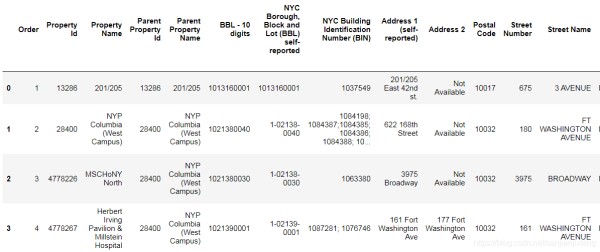
data.info()
python
运行
将Not Available转换为np.nan,再将部分数值型数据转换成float
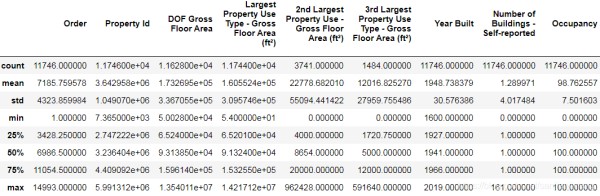
data = data.replace({ 'Not Available': np.nan}) for col in list(data.columns): if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in col or 'therms' in col or 'gal' in col or 'Score' in col):data[col] = data[col].astype(float) data.describe()
python
运行
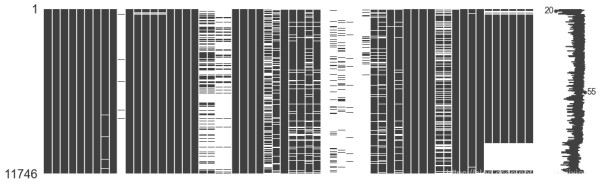
import missingno as msno msno.matrix(data, figsize = (16, 5))
python
运行
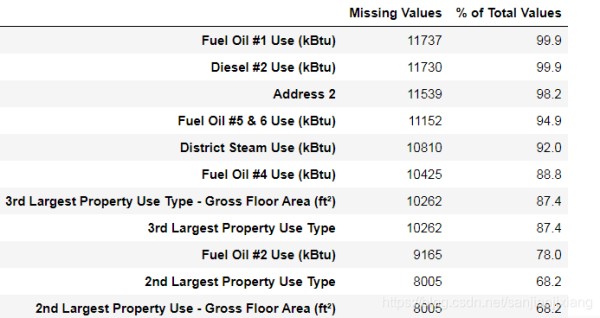
def missing_values_table(df):mis_val = df.isnull().sum() # 总缺失值 mis_val_percent = 100 * df.isnull().sum() / len(df) # 缺失值比例 mis_val_table = pd.concat([mis_val, mis_val_percent], axis = 1) # 缺失值制成表格 mis_val_table_ren_columns = mis_val_table.rename(columns = { 0:'Missing Values', 1:'% of Total Values'}) mis_val_table_ren_columns = mis_val_table_ren_columns[ mis_val_table_ren_columns.iloc[:,1] != 0].sort_values('% of Total Values',ascending=False).round(1) # 缺失值比例列由大到小排序 print('Your selected dataframe has {} columns.\nThere are {} columns that have missing values.'.format(df.shape[1], mis_val_table_ren_columns.shape[0])) # 打印缺失值信息 return mis_val_table_ren_columns missing_values_table(data)
python
运行
Your selected dataframe has 60 columns.
There are 46 columns that have missing values.
missing_df = missing_values_table(data) missing_columns = list(missing_df[missing_df['% of Total Values'] > 50].index) print('We will remove %d columns.' % len(missing_columns))
python
运行
Your selected dataframe has 60 columns.
There are 46 columns that have missing values.
We will remove 11 columns.
data = data.drop(columns = list(missing_columns))
python
运行
二. 探索性数据分析
Exploratory Data Analysis, 就是画图来理解数据。。。
2.1 单变量绘图 标签数据data = data.rename(columns = { 'ENERGY STAR Score': 'score'}) plt.figure(figsize = (8, 6)) plt
python
运行

