Pandas数据分析:数据清洗与处理工具 #生活技巧# #工作学习技巧# #编程语言学习路径#
最新推荐文章于 2024-09-18 11:52:30 发布
原创 于 2021-02-18 21:27:32 发布 · 255 阅读
· 0
· 0 ·
CC 4.0 BY-SA版权
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
 这篇博客详细介绍了在数据分析中如何处理缺失值和重复值。使用`isnull()`和`notnull()`可以快速定位缺失值,`fillna()`允许填充缺失值,而`dropna()`则能删除含有缺失值的行或列。对于重复值,`duplicated()`用于检查,`drop_duplicates()`用于删除。`dropna()`和`drop_duplicates()`提供了多种参数选项,如`axis`、`how`、`subset`和`inplace`,以灵活地处理数据。此外,还讲解了`fillna()`的`value`和`method`参数,用于设定填充方式和值。这些方法对于数据预处理至关重要。
这篇博客详细介绍了在数据分析中如何处理缺失值和重复值。使用`isnull()`和`notnull()`可以快速定位缺失值,`fillna()`允许填充缺失值,而`dropna()`则能删除含有缺失值的行或列。对于重复值,`duplicated()`用于检查,`drop_duplicates()`用于删除。`dropna()`和`drop_duplicates()`提供了多种参数选项,如`axis`、`how`、`subset`和`inplace`,以灵活地处理数据。此外,还讲解了`fillna()`的`value`和`method`参数,用于设定填充方式和值。这些方法对于数据预处理至关重要。
摘要生成于 C知道 ,由 DeepSeek-R1 满血版支持, 前往体验 >
Null的处理方法
isnull() #返回表明那些是缺失值的布尔值
notnull() #isnull()的反函数
fillna()
dropna()
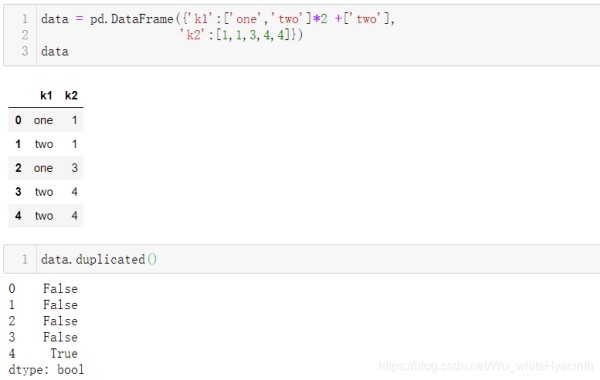
#查找重复值
data.duplicated()
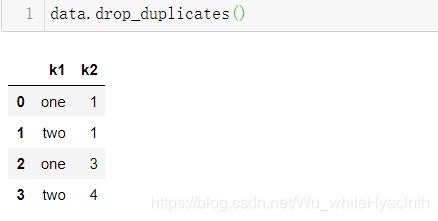
删除重复值
data.drop_duplicates()
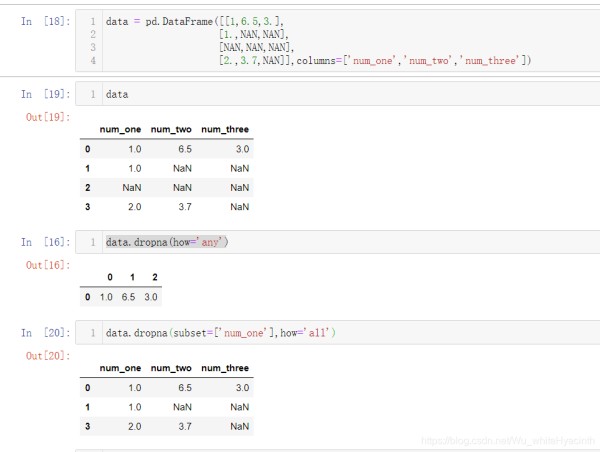
(1)data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) 说明:其中axis通常为0,
how=['any','all'],其中any就是只要有一个是null,那么就drop这一行,all是指一行的所有值为null
subset是根据指定的列名来判断是否为null
inplace;函数返回的是视图,不改变原始值,当 inplace=True时,原始值也会被改变
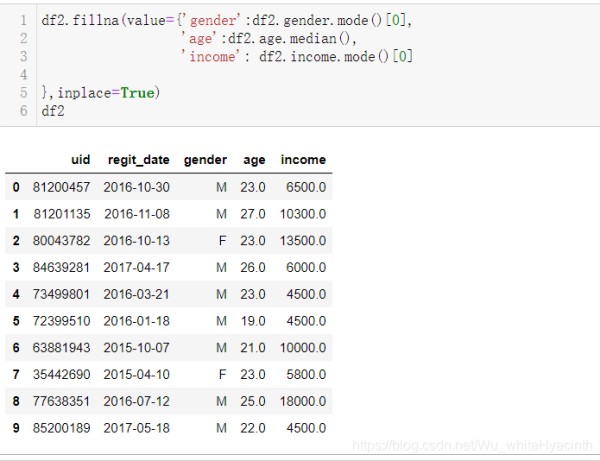
(2) df.fillna() df.fillna(
value=None, #字典{列名:填充值}
method=None, #插值方法,ffill(默认),bfill,ffill将前一个值;来填充null,bfill用后一个值来填充null
axis=0, #
inplace=False,
limit=None,
downcast=None,
)

(3) data.duplicated( subset:[ ], keep= 'first' ) data.drop_duplicates( subset:[ ], keep= 'first' ) keep: 'first' (默认)or 'last',选择保留重复值的第一个或者最后一个
\
网址:pandas数据清洗与准备 https://www.yuejiaxmz.com/news/view/1229024
相关内容
Pandas如虎添翼!数据清洗新神器PyjanitorPandas的数据清洗Pandas 数据处理实战AI数据清洗:提升效率与准确性的革命性方法湖南好课优选教育科技有限公司:Python 与Pandas数据处理的搭档从0到1数据分析实战学习笔记(二)数据清洗Python pandas 数据清洗(二)数据清洗:最佳实践与工具推荐Tableau Prep: 高效数据准备与清洗工具高效数据准备与清洗工具Trifacta
随便看看

