从 0 到 1 搞懂时序数据库选型:特性拆解 + 主流产品对比
检查产品序列号或条形码,与官方数据库对比 #生活知识# #购物技巧# #品牌鉴别方法#

从 0 到 1 搞懂时序数据库选型:特性拆解 + 主流产品对比
该指南围绕时序数据高写入、海量存储、时间维度查询等特性,提出性能(吞吐量、查询速度)、功能(数据模型、集成能力)、可靠性(高可用、容灾)、成本(硬件、维护)、扩展性(水平扩容)五大选型维度。通过对比 Apache IoTDB、InfluxDB 等主流数据库的特点与适用场景,建议按需求优先级测试选型,优先选择社区活跃、适配业务的产品,帮助用户找到高效管理时序数据的 “最佳拍档”。

在物联网、工业监控、能源电力等领域,每时每刻都在产生海量与时间紧密相关的数据——温度变化、设备运行状态、电力波动……这些时序数据如同源源不断的溪流,需要专门的“容器”来高效存储、管理和分析。时序数据库(Time Series Database, TSDB)便是为此而生的利器。然而,市面上的时序数据库种类繁多,如何选出最适合自己的那一款?本文将从时序数据的特性出发,结合主流选型维度,为你梳理选型思路。
一、先搞懂:时序数据为什么“挑”数据库?
时序数据的核心特点是**“与时间强绑定”**,并伴随高频写入、海量存储、按时间范围查询等需求。与传统关系型数据库(如MySQL)或NoSQL数据库(如MongoDB)相比,它对数据库有更“苛刻”的要求:
高写入吞吐量:传感器、设备可能每秒产生数千条数据,数据库需“接得住”;高效存储:时序数据按时间线性增长,需支持数据压缩,降低硬件成本;时间维度查询优化:常需查询“某时间段内的设备温度变化”,需快速定位时间范围数据;数据生命周期管理:旧数据可能需归档或删除,需支持自动过期策略。传统数据库在这些场景下往往“力不从心”:写入速度跟不上、存储成本高、查询耗时久。因此,专门为时序数据设计的数据库才是最优解。
二、选型核心维度:从需求匹配“硬指标”
选择时序数据库时,需围绕自身业务场景,重点关注以下维度:
1. 性能:能否扛住“数据洪流”? 写入吞吐量:每秒能处理多少条数据?例如工业生产线可能需要每秒处理10万+条设备数据,需数据库支持高并发写入。查询速度:查询某设备一周内的历史数据需多久?是否支持复杂聚合查询(如平均值、最大值)?存储效率:数据压缩率如何?例如Apache IoTDB的TsFile格式专为时序数据设计,压缩率比普通文件高3-5倍,可大幅降低存储成本。 2. 功能:是否满足“个性化需求”? 数据模型:是否支持设备层级结构(如“root.工厂.车间.设备”)?这对物联网场景的设备管理至关重要。查询语义:是否支持时间窗口函数、插值填充(如缺失数据补全)?例如Apache IoTDB提供丰富的时序查询语法,可直接计算“每小时平均温度”。集成能力:能否与主流工具联动?如对接Grafana做可视化、与Spark做数据分析、通过JDBC连接应用程序。 3. 可靠性:数据会不会“丢”? 高可用性:是否支持集群部署?单点故障时能否自动切换?例如集群模式下,Apache IoTDB的多个节点可互为备份,避免数据丢失。数据一致性:分布式场景下,数据同步是否准确?容灾能力:是否支持数据备份与恢复? 4. 成本:是否“性价比”最优? 硬件成本:是否可运行在普通服务器上?例如Apache IoTDB对硬件要求较低,中小规模场景无需高端服务器。维护成本:部署、配置是否简单?是否有活跃社区支持?开源数据库(如Apache IoTDB、InfluxDB OSS)通常比商业产品更易降低成本。 5. 扩展性:能否“长大”? 水平扩展:数据量从百万级增长到亿级时,能否通过增加节点扩容?功能扩展:是否支持用户自定义函数(UDF)?例如Apache IoTDB允许用户编写自定义分析函数,满足特定业务需求。三、主流时序数据库对比:哪款适合你?
数据库特点适用场景Apache IoTDB开源、轻量、高压缩率、支持丰富时序查询,与Hadoop/Spark生态兼容物联网、工业监控、中小规模时序数据场景InfluxDB开源版本功能基础,商业版支持集群和高可用,社区活跃初创公司、非核心业务场景TimescaleDB基于PostgreSQL,支持SQL语法,兼容关系型数据库生态熟悉PostgreSQL、需混合时序与关系数据的场景Prometheus专为监控设计,擅长指标收集与告警,与Grafana联动性好服务器、应用监控场景四、选型建议:三步找到“最佳拍档”
明确需求优先级:
若成本优先:选开源产品(如Apache IoTDB、InfluxDB OSS);若稳定性优先:商业版或成熟开源集群方案(如TDengine、Apache IoTDB集群);若监控场景:直接用Prometheus。小范围测试:
用实际业务数据测试写入速度、查询延迟、存储占用,例如用10万条设备数据测试Apache IoTDB的批量写入性能,观察是否满足需求。
关注长期支持:
选择社区活跃、文档完善的项目(如Apache IoTDB有官方中文文档和社区支持),避免后期维护困难。
五、时序数据库IoTDB
Apache IoTDB 是一款由 Apache 软件基金会孵化并推出的开源时序数据库,专为高效管理海量时序数据而生,其设计理念围绕“高性能、低成本、易使用”展开,在物联网、工业监控、能源电力等领域展现出强大的适配能力。

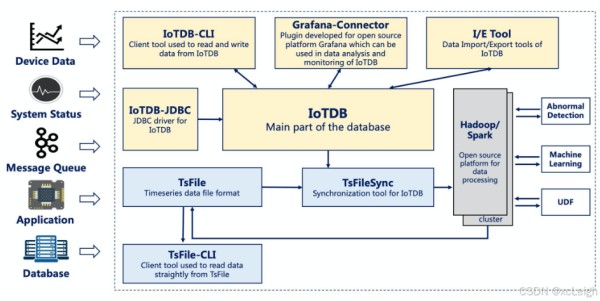
从核心架构来看,IoTDB 采用分层设计,包含多个关键组件协同工作:底层的 TsFile 是专为时序数据定制的存储格式,通过高效压缩算法(如Delta编码、RLE编码等)显著降低存储成本,同时支持按时间范围快速检索;中间层的 IoTDB 内核 负责数据的读写调度、元数据管理和查询优化,能实现高吞吐量的连续写入(每秒可处理数十万条数据)和低延迟的时间范围查询;上层则提供丰富的交互接口,包括 IoTDB-CLI 命令行工具、JDBC 驱动、Grafana 连接器等,方便用户通过多种方式操作数据,还支持与 Hadoop、Spark 等大数据平台集成,满足离线分析和机器学习需求。
在数据模型方面,IoTDB 采用“树形结构”组织数据,以“存储组-设备-测点”的层级关系映射现实世界的物理实体(如“root.工厂A.车间B.设备1.temperature”),既符合物联网设备的层级管理逻辑,又能通过路径前缀快速筛选同类设备数据,大幅提升查询效率。
功能特性上,IoTDB 具备三大核心优势:一是 极致的性能,针对时序数据的写入特点优化了内存管理和磁盘IO,单机即可支撑百万级传感器的并发数据采集;二是 丰富的查询能力,支持时间窗口聚合(如每5分钟平均温度)、插值填充(处理缺失数据)、时序对齐等特色操作,且SQL语法贴近用户习惯,降低学习成本;三是 灵活的部署方式,既支持单机模式满足中小规模场景,也可通过集群部署实现数据分片存储和负载均衡,确保系统高可用。
六、实战操作:4个常用命令,搞定数据增删查
学会了安装配置,咱们来实操一下,用4个常用命令,轻松搞定数据管理:

先得创建一个时间序列,才能存数据。比如给"sg1"设备组下的"d1"设备,建一个"temperature"(温度)序列,数据类型是FLOAT(浮点型),编码用RLE:
CREATE TIMESERIES root.sg1.d1.temperature WITH DATATYPE=FLOAT, ENCODING=RLE;
sql
1执行完没报错,就说明"家"建好了。
2. 插入数据:给"家"添点东西比如插入一条时间戳为1637289818000(对应2021-11-19 10:03:38)、温度为22.5的数据:
INSERT INTO root.sg1.d1(timestamp, temperature) VALUES (1637289818000, 22.5);
sql
1想多插几条,就在VALUES后面加逗号接着写,比如:
INSERT INTO root.sg1.d1(timestamp, temperature) VALUES (1637289819000, 23.1), (1637289820000, 22.8);
sql
1 3. 查询数据:看看"家里"有啥想查某个时间段的温度数据,比如查1637289818000到1637289900000之间的数据:
SELECT * FROM root.sg1.d1 WHERE time >= 1637289818000 AND time <= 1637289900000;
sql
1执行后就能看到这段时间的所有温度数据,速度超快,秒出结果。
4. 删除数据:不想要的"东西"删掉要是想删某个时间序列(比如不用温度序列了),执行这条命令:
DELETE TIMESERIES root.sg1.d1.temperature;
sql
1删完后这个序列就没了,注意别删错了,删了可就找不回来了!
此外,IoTDB 拥有活跃的开源社区和完善的文档支持,提供从数据导入导出、异常检测到用户自定义函数(UDF)的全链路工具链,无论是数据库新手还是资深开发者,都能快速上手并根据业务需求扩展其功能,堪称时序数据管理的“全能管家”。
时序数据管理的核心是“高效”与“适配”,没有万能的数据库,只有最适合业务的选择。希望本文能帮你找到那位得力的“时序数据管家”,让数据真正为业务赋能!
了解博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
关注博主 带你实现畅游前后端!
大屏可视化 带你体验酷炫大屏!
神秘个人简介 带你体验不一样得介绍!
从零到一学习Python 带你玩转技术流!
前沿应用深度测评 前沿AI产品热门应用在线等你来发掘!
注:本文撰写于CSDN平台,作者:xcLeigh(所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复
网址:从 0 到 1 搞懂时序数据库选型:特性拆解 + 主流产品对比 https://www.yuejiaxmz.com/news/view/1361431
相关内容
一个数字出版外行眼中的出版数据库产品营销拆解个性化推荐
时间序列数据库的分析与优化
数据驱动的数字化转型:从流程驱动到数据驱动
数据中台、数据仓库、数据治理与主数据的定位与差异
个人品牌打造:从0到1低成本创业
如何在生产环境mysql删除亿万级数据解并且不影响数据库主从延迟的解决方案
商业数据分析从入门到入职(1)商业数据分析综述
1年赚100万的实操项目:数字产品
Oracle数据库数据安全面面观
随便看看
最新动态分享
- 生活中护理肌肤的小妙招有哪些?
- 9大日常护肤养颜小妙招 让青春常相伴
- 5个皮肤补水方法滋润皮肤很给力
- 20个超实用生活小妙招,简单又省钱,解决日常大半烦恼
- 棉签竟然有这么多用处?你绝对想不到的日常小妙招!
- 如何全方位控油:护肤、饮食与生活习惯的综合指南?
- 大学生最常用的化妆品品牌TOP10,和你想的不同
- 史上最全旅游化妆品打包指南(GucciS出行必备)
- 常用化妆品有那些? 解析日常常用化妆品,打造美丽无瑕的肌肤秘笈
- 脸上毛孔粗大怎么办4个生活收缩毛孔小妙招介绍
热点动态分享
- 144912
- 50444
- 44866
- 42254
- 40655
- 30739
- 25341
- 25312
- 21734
- 18433

