【毕业设计】基于YOLO的工地工人安全作业操作检测 人工智能 深度学习 Python 目标检测
人工智能在金融风控中用于欺诈检测,提升安全性 #生活知识# #科技生活# #人工智能应用#
一、背景意义
随着建筑行业的快速发展,工地安全问题日益受到重视。工人安全装备的穿戴,如安全帽和反光背心,直接关系到工人的生命安全。然而,在实际施工环境中,常常出现工人未佩戴安全装备的情况,导致安全隐患增加。利用深度学习技术开发一套能自动识别工人安全作业检测系统显得尤为重要。本项目的数据集包含多种分类:安全帽、未佩戴安全帽、未穿反光背心、工人和反光背心。通过实时监测工人的安全装备穿戴情况,管理人员能够及时发现并纠正不符合安全标准的行为,降低事故发生率。该系统能有效识别未佩戴安全装备的工人,提醒工人及时穿戴,确保其在施工现场的安全。
二、数据集
2.1数据采集
首先,需要大量的安全装备类图像。为了获取这些数据,可以采取了以下几种方式:
网络爬虫:使用Python的BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示安全装备类特征是数据质量的关键。
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
分类任务:为每个数据样本分配类别标签。目标检测:标注图像中的每个目标,通常使用边界框。语义分割:为每个像素分配一个类别标签。在使用LabelImg标注工地工人安全装备穿戴数据集的过程中,标注者面临数据量庞大和工地环境复杂性带来的挑战。每张图像的标注可能耗时数分钟,标注者需准确识别安全帽、未佩戴安全帽、反光背心及未穿反光背心等细微差别。此外,标注后需进行复核,以确保标注的一致性和准确性。这一过程虽然工作量巨大,但高质量的标注对后续模型训练至关重要,直接影响工人安全装备的识别效果和效率。

包含1206张安全装备图片,数据集中包含以下几种类别
安全帽:指佩戴安全帽的人员。未佩戴安全帽:指未佩戴安全帽的人员。未穿反光背心:指未穿反光背心的人员。人员:在工地上工作的人员。反光背心:指穿着反光背心的人员。2.3数据预处理
数据预处理是为模型训练准备数据的关键步骤,主要包括以下内容:
图像格式转换:将收集到的图像转换为统一的格式(如JPEG或PNG),并调整为相同的尺寸,以便于模型输入。
数据增强:通过旋转、缩放、翻转、裁剪等方式对图像进行数据增强,增加样本数量,提高模型的鲁棒性和泛化能力。
归一化处理:对图像像素值进行归一化处理,将其缩放到0到1之间,以加速模型训练过程,确保训练过程的稳定性。
划分数据集:将数据集划分为训练集、验证集和测试集,以确保每个集的样本能够代表整体数据分布,便于后续模型训练和评估。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
VOC格式 (XML)YOLO格式 (TXT)yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...
三、模型训练
3.1理论技术
在工人安全作业监测系统中,CNN可以通过以下步骤进行应用:
数据采集:系统首先通过摄像头采集工人在作业过程中的实时视频或图像数据。这些数据可能包括工人的动作、工具的使用情况以及工作环境的变化。
数据预处理:采集到的图像数据需要经过预处理,以去除噪声、调整图像大小和格式。这一步骤通常包括图像增强、归一化以及数据扩增,以提高模型的鲁棒性。
特征提取:利用CNN进行特征提取,卷积层通过卷积核扫描图像,提取出工人动作和环境特征。随着网络层次的加深,模型能够学习到越来越复杂的特征,如工人的姿态、动作细节和工具的使用状态。
分类与检测:经过特征提取后,CNN将输出特征图,接着通过全连接层进行分类,判断工人当前的行为是否安全。例如,可以将工人的行为分为“安全”、“危险”或“需要注意”等类别。
实时监测与反馈:监测系统可以实时分析工人的行为,并在检测到危险行为时,立即发出警报,提醒工人注意安全。同时,系统可以记录危险事件的数据,为后续分析提供依据。

CNN通常采用以下计算方法:
卷积操作:使用卷积核对输入图像进行滑动操作,计算局部区域的特征。卷积操作可以有效提取图像的边缘、角点和纹理特征。
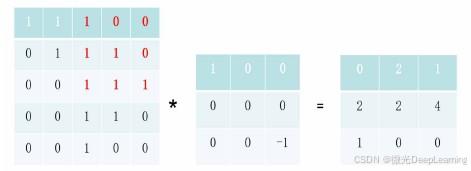
激活函数:在每个卷积层后应用激活函数(如ReLU),引入非线性,增强模型的表达能力。
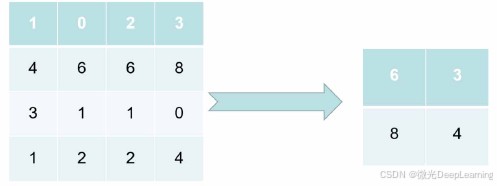
池化层:通过最大池化或平均池化层对卷积层的输出进行下采样,减少特征图的尺寸,降低计算复杂度,同时保留重要特征。
损失函数与优化算法:使用交叉熵损失函数(对于分类任务)评估模型的预测效果,并通过优化算法(如Adam或SGD)更新网络权重,以最小化损失。
迁移学习:在数据量不足时,可以使用预训练的CNN模型(如VGG、ResNet)进行迁移学习,以加快训练速度并提高模型的精度。
3.2模型训练
在工地工人安全装备穿戴识别系统的数据集划分和准备完成后,开发一个基于YOLO项目通常涉及几个关键步骤。
首先,环境配置是开发YOLO项目的第一步。确保所有必要的库和工具已正确安装。这一过程通常在虚拟环境中进行,以避免与其他项目的依赖冲突。安装深度学习框架(如PyTorch或TensorFlow)以及YOLO所需的相关库非常重要。可以通过命令行创建并激活虚拟环境,然后使用pip安装所需的库,以确保YOLO项目顺利运行。
# 创建并激活虚拟环境
python -m venv yolov5_env
source yolov5_env/bin/activate # Linux/Mac
# yolov5_env\Scripts\activate # Windows
# 安装必要的库
pip install torch torchvision
pip install opencv-python
pip install matplotlib
pip install pandas
pip install tqdm
接下来,准备数据集配置文件和超参数设置是至关重要的一步。数据集配置文件需要包含类别信息及其路径,以便YOLO模型能够正确加载数据。通常使用YAML格式来描述数据集的结构,确保每个类别的名称与数据集中标注一致。此外,还需要设置训练的超参数,如学习率、批次大小等,以优化模型的训练效果。
train: ./train/images
val: ./val/images
nc: 5
names: ['安全帽', '未佩戴安全帽', '未穿反光背心', '工人', '反光背心']
模型训练是YOLO项目的核心步骤。通过调用YOLO的训练函数,指定使用的数据集、训练图像的大小及其他参数。训练的目标是通过不断调整模型权重,最小化损失函数,从而提高模型在特定任务上的准确性。该步骤需要耐心,因为训练过程可能需要几小时到几天,具体取决于数据集的大小和模型的复杂性。
import torch
from yolov5 import train
# 设置训练参数
train.run(
data='data.yaml', # 数据集配置文件
imgsz=640, # 输入图像大小
batch=16, # 每批次图像数量
epochs=50, # 训练轮数
weights='yolov5s.pt', # 预训练模型
workers=4 # 数据加载线程数
)
训练完成后,需要对模型的性能进行评估。通过在验证集上测试模型的表现,评估指标包括准确率、召回率和F1分数等。使用YOLO提供的评估函数,可以加载训练好的模型权重,并在验证集上进行推理,生成评估报告。这一环节至关重要,有助于了解模型在不同类别上的识别能力及其鲁棒性。
from yolov5 import val
# 评估模型
val.run(
weights='runs/train/exp/weights/best.pt', # 最佳模型权重
data='data.yaml', # 数据集配置文件
imgsz=640, # 输入图像大小
conf_thres=0.25, # 置信度阈值
iou_thres=0.45 # IOU阈值
)
一旦模型经过训练和评估,接下来是使用训练好的模型进行推理,对新图像进行检测,并可视化结果。这一过程验证模型的实际效果,能够展示其能力。通过读取待检测的图像,模型会返回检测结果,并将目标框选出来,帮助开发者理解模型的实际表现。
import cv2
import torch
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt')
img = cv2.imread('test_image.jpg')
results = model(img)
results.show()
results.save('output')
四、总结
利用深度学习技术,实时监测工人是否佩戴安全装备,提升施工安全性。该系统的数据集包含五个主要分类:安全帽、未佩戴安全帽、未穿反光背心、工人和反光背心。通过对图像进行数据采集、清洗、标注和预处理,确保数据的高质量和多样性。在系统开发中,首先进行环境配置,确保安装所需的深度学习框架与YOLO相关库。接着,通过配置数据集文件和超参数,开展模型训练。训练完成后,通过评估模型性能,验证其在不同场景下的识别能力。最后,模型推理和结果可视化使得监测工作更加直观和高效。
网址:【毕业设计】基于YOLO的工地工人安全作业操作检测 人工智能 深度学习 Python 目标检测 https://www.yuejiaxmz.com/news/view/1385838
相关内容
基于深度学习的维修工具检测识别系统【完结】基于深度学习的工业压力表智能检测与读数系统【4】Pyqt5制作系统软件界面
基于YOLOv12的家务机器人目标检测系统设计与实现(Cup/Plate检测)
嵌入式设备上的实时目标检测:YOLO Tiny优化技巧
基于Python的智能健康管理与监测系统设计与实现 毕业设计开题报告
基于Python实现智能环境监测系统计算机毕设
基于深度学习的生活垃圾检测与分类系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
python+flask框架的基于人工智能的个人健康管理系统设计(开题+程序+论文) 计算机毕业设计
垃圾分类检测数据集
基于深度学习的盲人行路辅助软件设计
随便看看
最新动态分享
- 地板去污小妙招
- 地板去污方法是什么?
- 木地板陈年污垢清洁妙招(木地板陈年污垢清洁妙招有哪些)
- 宇文芊兰:如何清洁木地板上的红酒渍? 以下是一些清洁木地板上红酒渍的生活小妙招: 一、盐和苏打粉 1. 首先,在红酒渍上撒上大量的盐,盐可以吸收红酒中的水分,有助于防止红酒渍进一步渗入木地板。 2. 等待几分钟,让盐充分吸收红酒渍中的水分。 3. 然后,用湿布将盐轻轻擦去。 4. 接着,将苏打粉和水混合制成糊状物。苏打粉有去污和中和酸性物质(红酒是酸性的)的作用。 5. 把糊状物涂抹在...
- 地上的顽固污垢怎么清除
- 100个公众号爆文案例拆解库
- 史上最全!100个家庭去污公式整理,赶紧收藏留用
- 保洁阿姨教的拖地技巧:用这5个小妙招,地板一周不落灰,光洁如新!
- Linux命令详解:od(八进制dump)转换文件格式与参数指南
- 公众号10万+爆文都在哪找?我发现了最快捷的方法
热点动态分享
- 145062
- 52130
- 45089
- 42459
- 40892
- 30873
- 25630
- 25515
- 21894
- 18586

