基于卷积神经网络(CNN)模型的垃圾分类设计与实现
深度学习中,卷积神经网络(CNN)常用于图像识别任务 #生活技巧# #学习技巧# #深度学习技巧#
本篇博客主要内容如下:
目录
项目背景
数据集介绍
模型构建与训练
结果分析
结果对比分析
项目背景
如何通过垃圾分类管理,最大限度地实现垃圾资源利用,减少垃圾处置量,改善生存环境质量,是当前世界各国共同关注的迫切问题之一。根据国家制定的统一标准,现在生活垃圾被广泛分为四类,分别是可回收物、餐厨垃圾、有害垃圾和其他垃圾。可回收物表示适宜回收和资源利用的垃圾,主要包括废纸、塑料、玻璃、金属和布料五大类,用蓝色垃圾容器收集,通过综合处理回收利用。餐厨垃圾包括剩菜剩饭、骨头、菜根菜叶、果皮等食品类废物,用绿色垃圾容器收集等等。但是随着深度学习技术的发展,为了简单高效地对生活垃圾进行识别分类,本篇文章将实现一种基于卷积神经网络的垃圾分类识别方法。该方法只需要对图像进行简单的预处理,CNN模型便能够自动提取图像特征且池化过程能够减少参数数量,降低计算的复杂度,实验结果表明卷积神经网络,能克服传统图像分类算法的诸多缺点,当然更为复杂的模型等待大家去实验研究,讨论研究Q525894654。但是目前认为采用VGG或者global 池化方式可能效果更好一点。
数据集介绍
数据描述:
数据集一共包括四大类垃圾,分别为:其他垃圾,厨余垃圾、可回收垃圾及有害垃圾,并对其四大类进行了细致分类。具体描述如下:
"0": "其他垃圾/一次性快餐盒",
"1": "其他垃圾/污损塑料",
"2": "其他垃圾/烟蒂",
"3": "其他垃圾/牙签",
"4": "其他垃圾/破碎花盆及碟碗",
"5": "其他垃圾/竹筷",
"6": "厨余垃圾/剩饭剩菜",
"7": "厨余垃圾/大骨头",
"8": "厨余垃圾/水果果皮",
"9": "厨余垃圾/水果果肉",
"10": "厨余垃圾/茶叶渣",
"11": "厨余垃圾/菜叶菜根",
"12": "厨余垃圾/蛋壳",
"13": "厨余垃圾/鱼骨",
"14": "可回收物/充电宝",
"15": "可回收物/包",
"16": "可回收物/化妆品瓶",
"17": "可回收物/塑料玩具",
"18": "可回收物/塑料碗盆",
"19": "可回收物/塑料衣架",
"20": "可回收物/快递纸袋",
"21": "可回收物/插头电线",
"22": "可回收物/旧衣服",
"23": "可回收物/易拉罐",
"24": "可回收物/枕头",
"25": "可回收物/毛绒玩具",
"26": "可回收物/洗发水瓶",
"27": "可回收物/玻璃杯",
"28": "可回收物/皮鞋",
"29": "可回收物/砧板",
"30": "可回收物/纸板箱",
"31": "可回收物/调料瓶",
"32": "可回收物/酒瓶",
"33": "可回收物/金属食品罐",
"34": "可回收物/锅",
"35": "可回收物/食用油桶",
"36": "可回收物/饮料瓶",
"37": "有害垃圾/干电池",
"38": "有害垃圾/软膏",
"39": "有害垃圾/过期药物"
数据标签与统计结果:
类别:0 该类别总样本数:469 训练集样本数:375 验证集样本数:94
类别:1 该类别总样本数:471 训练集样本数:376 验证集样本数:95
类别:2 该类别总样本数:440 训练集样本数:352 验证集样本数:88
类别:3 该类别总样本数:150 训练集样本数:120 验证集样本数:30
类别:4 该类别总样本数:458 训练集样本数:366 验证集样本数:92
类别:5 该类别总样本数:413 训练集样本数:330 验证集样本数:83
类别:6 该类别总样本数:463 训练集样本数:370 验证集样本数:93
类别:7 该类别总样本数:422 训练集样本数:337 验证集样本数:85
类别:8 该类别总样本数:455 训练集样本数:364 验证集样本数:91
类别:9 该类别总样本数:482 训练集样本数:385 验证集样本数:97
类别:10 该类别总样本数:474 训练集样本数:379 验证集样本数:95
类别:11 该类别总样本数:806 训练集样本数:644 验证集样本数:162
类别:12 该类别总样本数:450 训练集样本数:360 验证集样本数:90
类别:13 该类别总样本数:466 训练集样本数:372 验证集样本数:94
类别:14 该类别总样本数:448 训练集样本数:358 验证集样本数:90
类别:15 该类别总样本数:514 训练集样本数:411 验证集样本数:103
类别:16 该类别总样本数:459 训练集样本数:367 验证集样本数:92
类别:17 该类别总样本数:740 训练集样本数:592 验证集样本数:148
类别:18 该类别总样本数:462 训练集样本数:369 验证集样本数:93
类别:19 该类别总样本数:491 训练集样本数:392 验证集样本数:99
类别:20 该类别总样本数:284 训练集样本数:227 验证集样本数:57
类别:21 该类别总样本数:825 训练集样本数:660 验证集样本数:165
类别:22 该类别总样本数:452 训练集样本数:361 验证集样本数:91
类别:23 该类别总样本数:415 训练集样本数:332 验证集样本数:83
类别:24 该类别总样本数:424 训练集样本数:339 验证集样本数:85
类别:25 该类别总样本数:781 训练集样本数:624 验证集样本数:157
类别:26 该类别总样本数:464 训练集样本数:371 验证集样本数:93
类别:27 该类别总样本数:623 训练集样本数:498 验证集样本数:125
类别:28 该类别总样本数:485 训练集样本数:388 验证集样本数:97
类别:29 该类别总样本数:479 训练集样本数:383 验证集样本数:96
类别:30 该类别总样本数:388 训练集样本数:310 验证集样本数:78
类别:31 该类别总样本数:496 训练集样本数:396 验证集样本数:100
类别:32 该类别总样本数:376 训练集样本数:300 验证集样本数:76
类别:33 该类别总样本数:373 训练集样本数:298 验证集样本数:75
类别:34 该类别总样本数:517 训练集样本数:413 验证集样本数:104
类别:35 该类别总样本数:443 训练集样本数:354 验证集样本数:89
类别:36 该类别总样本数:297 训练集样本数:237 验证集样本数:60
类别:37 该类别总样本数:380 训练集样本数:304 验证集样本数:76
类别:38 该类别总样本数:445 训练集样本数:356 验证集样本数:89
类别:39 该类别总样本数:487 训练集样本数:389 验证集样本数:98
总类别数:40 总样本数:18967 训练集总样本数:15159 验证集总样本数:3808
模型构建与训练
模型构建代码:model.py
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, MaxPooling2D, Dropout, Activation, BatchNormalization
from keras import backend as K
from keras import optimizers, regularizers, Model
from keras.applications import vgg19, densenet
def generate_trashnet_model(input_shape, num_classes):
# create model
model = Sequential()
# add model layers
model.add(Conv2D(96, kernel_size=11, strides=4, activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=3, strides=2))
model.add(Conv2D(256, kernel_size=5, strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=3, strides=2))
model.add(Conv2D(384, kernel_size=3, strides=1, activation='relu'))
model.add(Conv2D(384, kernel_size=3, strides=1, activation='relu'))
model.add(Conv2D(256, kernel_size=3, strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=3, strides=2))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(4096))
model.add(Activation(lambda x: K.relu(x, alpha=1e-3)))
model.add(Dropout(0.5))
model.add(Dense(4096))
model.add(Activation(lambda x: K.relu(x, alpha=1e-3)))
model.add(Dense(num_classes, activation="softmax"))
# compile model using accuracy to measure model performance
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
# Generate model using a pretrained architecture substituting the fully connected layer
def generate_transfer_model(input_shape, num_classes):
# imports the pretrained model and discards the fc layer
base_model = densenet.DenseNet121(
include_top=False,
weights='imagenet',
input_tensor=None,
input_shape=input_shape,
pooling='max') #using max global pooling, no flatten required
x = base_model.output
#x = Dense(256, activation="relu")(x)
x = Dense(256, activation="relu", kernel_regularizer=regularizers.l2(0.01))(x)
x = Dropout(0.6)(x)
x = BatchNormalization()(x)
predictions = Dense(num_classes, activation="softmax")(x)
# this is the model we will train
model = Model(inputs=base_model.input, outputs=predictions)
# compile model using accuracy to measure model performance and adam optimizer
optimizer = optimizers.Adam(lr=0.001)
#optimizer = optimizers.SGD(lr=0.0001, momentum=0.9, nesterov=True)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
return model
Total params: 7,302,470
Trainable params: 7,218,310
Non-trainable params: 84,160
模型训练代码:train_test.py
from keras.preprocessing.image import ImageDataGenerator
from keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from model import *
#from google.colab import drive
import tensorflow as tf
import seaborn as sn
import pandas as pd
# parameters
img_width, img_height = 224, 224 # dimensions to which the images will be resized
n_epochs = 10
batch_size = 32
num_classes = 40 # categories of trash
#project_dir = '/cnn/data/'
project_dir = ''
trainset_dir = project_dir + 'dataset-splitted/training-set'
testset_dir = project_dir + 'dataset-splitted/test-set'
load_weights_file = project_dir + 'weights_save_densenet121_val_acc_86.0.h5'
save_weights_file = project_dir + 'weights_save_4.h5'
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
trainset_dir,
target_size=(img_width, img_height),
batch_size=batch_size)
test_generator = test_datagen.flow_from_directory(
testset_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
shuffle=False)
if K.image_data_format() == 'channels_first':
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
model = generate_transfer_model(input_shape, num_classes)
def load_weights():
model.load_weights(load_weights_file)
print("Weights loaded")
def fit(n_epochs):
history = model.fit_generator(
train_generator,
steps_per_epoch=len(train_generator),
epochs=n_epochs,
validation_data=test_generator,
validation_steps=len(test_generator))
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
model.save_weights(save_weights_file)
def print_layers():
for layer in model.layers:
print(layer.name)
print("trainable: " + str(layer.trainable))
print("input_shape: " + str(layer.input_shape))
print("output_shape: " + str(layer.output_shape))
print("_____________")
def print_classification_report():
# Confution Matrix and Classification Report
Y_pred = model.predict_generator(test_generator, len(test_generator))
y_pred = np.argmax(Y_pred, axis=1)
print('Classification Report')
target_names = list(test_generator.class_indices.keys())
print(classification_report(test_generator.classes, y_pred, target_names=target_names))
print('Confusion Matrix')
conf_mat = confusion_matrix(test_generator.classes, y_pred)
df_cm = pd.DataFrame(conf_mat, index=target_names, columns=target_names)
plt.figure(figsize=(10, 7))
sn.heatmap(df_cm, annot=True)
#save keras model and convert it into tflite model
def save_model():
# Save tf.keras model in HDF5 format.
keras_file = "keras_model.h5"
model.save(keras_file)
# Convert to TensorFlow Lite model.
converter = tf.lite.TFLiteConverter.from_keras_model_file(keras_file)
tflite_model = converter.convert()
open("converted_model.tflite", "wb").write(tflite_model)
print("saved")
#print_layers()
load_weights()
#fit(n_epochs)
print_classification_report()
#save_model()
结果分析
首先构建或者下载好数据集,直接运行train_test.py即可,训练十次左右的准确率与损失函数图像如下:
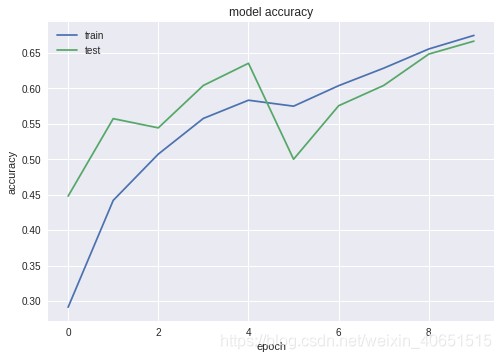
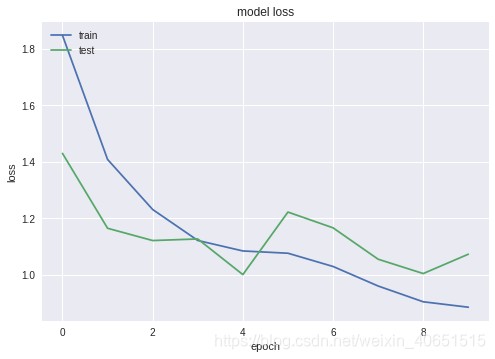
最终训练次数达到60次左右趋于稳定,准确率可达75%左右。该模型可根据需求更改为四分类问题,只需要修改numclass参数即可。
结果对比分析
该方法与传统的机器学习方法SVM相比,训练较慢,但是准确率较高,该数据集上高于6%-9%;
网址:基于卷积神经网络(CNN)模型的垃圾分类设计与实现 https://www.yuejiaxmz.com/news/view/1422819
相关内容
Python基于深度学习机器学习卷积神经网络实现垃圾分类垃圾识别系统(GoogLeNet,Resnet,DenseNet,MobileNet,EfficientNet,Shufflent)基于卷积神经网络的生活垃圾检测与分类方法研究
深入理解卷积神经网络(CNN):从简单到复杂的实现与优化
CNN优化全攻略:卷积神经网络性能提升的20条技巧
基于深度卷积神经网络的生活垃圾分类方法研究
论文阅读——基于深度学习智能垃圾分类
【故障诊断】基于贝叶斯优化卷积神经网络BO
毕业设计:基于机器学习的生活垃圾智能分类系统 多尺度特征融合 轻量型网络
卷积神经网络优化技巧:提升性能与降低复杂度1.背景介绍 卷积神经网络(Convolutional Neural Netw
详解卷网络(CNN)在语音识别中的应用
随便看看
最新动态分享
- 包河区置地瑰丽公馆售楼部电话号码(最新认证官方预约电话2026.6.26)
- 分馆动态|“碳”生活易,叹生活难?海珠区图书馆南附分馆用这套模式给出了答案
- 北京搬家必看科普:别把值钱旧货当垃圾丢!老酒、红木、钱币上门回收攻略
- 奢侈品媒体|拉夫劳伦男装封神之作|奢华奢侈媒体
- 家里的废旧物品不要乱扔,几乎什么都可以用到手工制作上
- 旧物巧变身 亲子共护绿一一信阳市光山县特教学校开展创意手工艺品创作评比活动
- 北京家庭处理闲置:选对机构,真的省心又放心
- 片上总线学习之Wishbone
- 国交院举办毕业季跳蚤市场暨国际文化节活动
- 足不出户旧物回收 废物利用
热点动态分享
- 143907
- 44911
- 44095
- 39697
- 37552
- 29218
- 24333
- 24157
- 20529
- 17675

