python爬虫之静态网页——全国空气质量指数(AQI)爬取
编写Python爬虫抓取网页数据 #生活知识# #编程教程#
首先爬取地址:http://www.air-level.com/
利用的python库,最近最流行的requests,BeautifulSoup。
requests:用于下载html
BeautifulSoup:用于解析
下面开始分析:要获取所有城市的aqi,就要进入每个城市的单独链接,而这些链接可以从主页中获取

打开主网页,查看源代码,可以看到,所有的城市链接都在id=‘citylist’里面
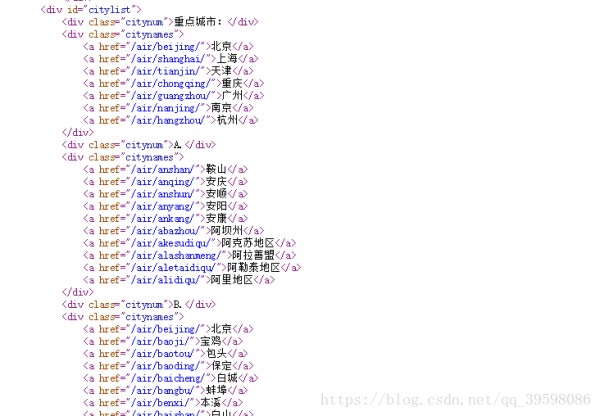
把所有链接爬下来存在一个列表里面,然后依次爬取每个城市的单个链接,附代码:
def get_all_city(): # 爬取城市链接
url = "http://www.air-level.com"
try:
kv = {'user-agent': 'Mozilla/5.0'} # 伪装成浏览器,headers
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print("爬取城市链接失败")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
time = soup.find('h4').string
print(time)
for it in soup.find(id="citylist").children:
if isinstance(it, bs4.element.Tag): # 检测it的类型,得是一个bs4.element.Tag类型
for its in it.find_all('a'):
clist.append(its.get('href')) # 加入列表当中去
cnlist.append(its.string)
html
之后就是每个城市的单独链接的信息爬取,以北京为例,查看源代码可知:

附爬取每个城市代码:
def get_one_page(city): # 获得HTML 爬取城市信息
url = "http://www.air-level.com"+city
if city in cwlink:
aqilist.append("异常链接")
else:
try:
kv = {'user-agent': 'Mozilla/5.0'} # 伪装成浏览器,headers
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print("爬取失败")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
s = soup.find("span")
aqilist.append(s.string)
html
但是在爬取的过程中会发现问题,有的一些城市网站用浏览器打不开,也就爬取不了,所以要做处理,
在上面可以看到,本人用cwlist存储了所有异常链接,跳过去,不爬取。
附完整代码:
import requests
from bs4 import BeautifulSoup
import bs4
aqilist = [] # 储存城市AQI
clist = [] # 储存城市链接
cnlist = [] # 储存城市名字
cwlink = ["/air/changdudiqu/", "/air/kezilesuzhou/", "/air/linzhidiqu/", "/air/rikazediqu/",
"/air/shannandiqu/", "/air/simao/", "/air/xiangfan/", "/air/yilihasake/"] # 异常链接
def get_one_page(city): # 获得HTML 爬取城市信息
url = "http://www.air-level.com"+city
if city in cwlink:
aqilist.append("异常链接")
else:
try:
kv = {'user-agent': 'Mozilla/5.0'} # 伪装成浏览器,headers
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print("爬取失败")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
s = soup.find("span")
aqilist.append(s.string)
def get_all_city(): # 爬取城市链接
url = "http://www.air-level.com"
try:
kv = {'user-agent': 'Mozilla/5.0'} # 伪装成浏览器,headers
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print("爬取城市链接失败")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
time = soup.find('h4').string
print(time)
for it in soup.find(id="citylist").children:
if isinstance(it, bs4.element.Tag): # 检测it的类型,得是一个bs4.element.Tag类型
for its in it.find_all('a'):
clist.append(its.get('href')) # 加入列表当中去
cnlist.append(its.string)
def main():
get_all_city()
print("共爬取了{}个城市".format(len(clist)))
for it in range(len(clist)):
get_one_page(clist[it])
print("{} {}".format(cnlist[it], aqilist[it]))
main()
html
简单的静态爬取就实现了
网址:python爬虫之静态网页——全国空气质量指数(AQI)爬取 https://www.yuejiaxmz.com/news/view/1427545
相关内容
python爬虫代码网页爬虫实战:全国电动汽车充电站数据
中国空气质量指数(AQI)及其计算方式
python爬虫与数据分析之《向往的生活爬取》
Python 爬虫实战:爬取丁香医生,获取专业健康知识打造医疗知识库
对未来空气质量指数(aqi)分析与预测
Python 网络爬虫实战:去哪儿网旅游攻略图文爬取保存为 Markdown电子书
批量python爬虫采集性能优化之减少网络延迟的方法
Python爬虫学习==>第五章:爬虫常用库的安装
Python爬虫抓取基金数据分析、预测系统设计与实现——云诺说
随便看看
最新动态分享
- 适合搭配的食材
- 食疗养生大全:67种天然食材搭配与食疗方,吃出健康好气色
- 哪些食材可以搭配食用 十对最佳食材搭配好吃又健康
- 壮阳补肾煲汤大全:中药配方与食材搭配全解析
- 广东鱼肚汤的家常做法大全|营养功效+食材搭配+5种经典汤谱(附详细步骤)
- 四季美容养颜豆浆配方大全|天然食材搭配+科学原理,喝出透亮肌
- 零失败家常小炒菜谱大全(附新手必学技巧+食材搭配指南)
- 补肾食谱大全:10种家常食疗方+食材清单,科学搭配提升肾动力
- 5种营养搭配!家常鸡汤快手做法大全(附不同做法+食材禁忌)
- 麻辣香锅食材菜单大全图
热点动态分享
- 144447
- 46591
- 44494
- 40183
- 39112
- 30255
- 24937
- 24711
- 21221
- 18126

