Transformer训练技巧:从学习率调度到梯度裁剪
通过调整学习率策略(如学习率衰减)控制模型训练速度 #生活技巧# #学习技巧# #深度学习技巧#
引言
Transformer模型凭借其强大的并行计算能力和对长距离依赖关系的建模能力,已成为自然语言处理领域的主流架构。然而,随着模型规模的不断扩大,训练过程中的诸多挑战也随之而来。例如,大规模模型的参数量激增,导致训练时间急剧延长;梯度更新的稳
定性难以控制,容易出现梯度爆炸或消失问题。这些问题的存在使得训练过程变得复杂且效率低下。
本文将围绕Transformer训练中的两个核心优化技巧展开讨论:学习率调度和梯度裁剪。我们将从理论到实践,深入探讨这两种技术的原理、应用场景以及具体实现方法,并结合实际案例展示它们在训练中的重要性。文章将通过代码示例、流程图和表格
等方式,帮助读者全面理解这些技巧,并在实际训练中灵活运用。
一、学习率调度:动态调整学习率的策略
1.1 学习率调度的必要性在深度学习训练中,学习率是影响模型收敛速度和最终性能的关键超参数。固定学习率(Constant Learning Rate)虽然简单,但在训练初期可能导致模型收敛缓慢,而在训练后期则可能无法有效微调模型参数。Transformer模型参数量庞大,训练过程复杂,固
定学习率难以适应不同训练阶段的需求。
学习率调度的核心思想是动态调整学习率,使其在训练的不同阶段发挥不同的作用。例如,在训练初期,使用较高的学习率可以加快模型收敛速度;而在训练后期,降低学习率有助于模型进一步优化,避免震荡收敛。
1.2 常见学习率调度策略 1.2.1 步长衰减(Step Decay)步长衰减策略是指每隔一定训练轮数(epoch),将学习率按固定比例降低。例如,初始学习率为0.1,每10个epoch将学习率降低为原来的0.5倍。这种策略简单易实现,但需要提前预设好衰减的轮数和比例,否则可能导致学习率调整不够灵活。
1.2.2 指数衰减(Exponential Decay)指数衰减策略根据训练轮数按指数函数逐步降低学习率。其公式为:
α=α0×e−kt \alpha = \alpha_0 \times e^{-kt} α=α0×e−kt
其中,α0\alpha_0α0为初始学习率,kkk为衰减率,ttt为训练轮数。这种方法对学习率的调整更平滑,但需要合理设置参数,否则可能导致学习率下降过快或过慢。
1.2.3 余弦退火(Cosine Annealing)余弦退火策略模拟余弦函数,将学习率从初始值逐渐降低到最小值。其公式为:
α=αmin+(αmax−αmin)×cos(TcurTmaxπ) \alpha = \alpha_{\min} + (\alpha_{\max} - \alpha_{\min}) \times \cos\left(\frac{T_{cur}}{T_{max}} \pi\right) α=αmin+(αmax−αmin)×cos(TmaxTcurπ)
其中,TcurT_{cur}Tcur为当前训练轮数,TmaxT_{max}Tmax为周期长度,αmax\alpha_{\max}αmax为初始学习率和最小学习率。余弦退火策略在训练初期学习率较高,后期逐渐降低,有助于模型在不同阶段保持良好的收敛性。
1.2.4 随机梯度裁剪(Stochastic Gradient Descent with Warm Restarts)该策略在训练过程中随机重启优化器,每次重启时重置学习率为初始值,并逐渐降低学习率上限。这种方法通过重启机制避免了模型陷入局部最优,同时通过学习率动态调整提高了模型的泛化能力。
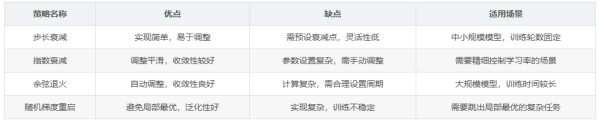
1.3 实践中的学习率调度策略在实际训练中,学习率调度策略的选择需要根据任务需求、模型规模和训练数据量灵活调整。以下是几种常用策略的对比表格:
策略名称优点缺点适用场景步长衰减实现简单,易于调整需预设衰减点,灵活性低中小规模模型,训练轮数固定指数衰减调整平滑,收敛性较好参数设置复杂,需手动调整需要精细控制学习率的场景余弦退火自动调整,收敛性良好计算复杂,需合理设置周期大规模模型,训练时间较长随机梯度重启避免局部最优,泛化性好实现复杂,训练不稳定需要跳出局部最优的复杂任务1.4 学习率调度的代码实现以下为PyTorch中实现余弦退火学习率调度器的代码示例:
import torch from torch.optim.lr_scheduler import LambdaLR def cosine_annealing(step, max_step, eta_min=0.0, eta_max=0.1): """余弦退火学习率函数""" return eta_min + (eta_max - eta_min) * (1 + torch.cos(torch.tensor(step * torch.pi / max_step))) # 假设optimizer是优化器,max_step为总训练步数 scheduler = LambdaLR(optimizer, lambda step: cosine_annealing(step, max_step=10000)) # 在训练循环中,每一步调用scheduler.step() # 注意:scheduler.step()需要在optimizer.step()之后调用
python
运行
123456789101112 1.5 学习率调度的流程图
二、梯度裁剪:防止梯度爆炸的利器
2.1 梯度爆炸问题在深度学习训练中,梯度爆炸(Gradient Explosion)是指梯度值过大,导致模型参数更新异常,进而使模型训练不稳定甚至发散。Transformer模型中,由于层数较深、参数量大,梯度爆炸问题尤为常见。例如,在训练大规模语言模型时,若某层梯度异常增大
,可能会导致模型参数更新幅度过大,进而影响模型性能。
梯度裁剪(Gradient Clipping)是一种通过限制梯度范数来防止梯度爆炸的技术。其核心思想是:当梯度范数超过设定阈值时,将梯度按比例缩放至阈值范围内。这种方法能够在不破坏梯度方向的前提下,有效抑制梯度爆炸。
2.3 梯度裁剪的方法 2.3.1 按梯度范数裁剪(Norm Clipping)按梯度范数裁剪是最常用的梯度裁剪方法。其公式为:
g′=gmax(∥g∥,clip_norm) g' = \frac{g}{\max(\|g\|, \text{clip\_norm})} g′=max(∥g∥,clip_norm)g
其中,ggg为原始梯度,g′g'g′为裁剪后的梯度,clip_norm\text{clip\_norm}clip_norm为设定的阈值。当梯度范数超过阈值时,梯度将被缩放至阈值范围内。
2.3.2 按梯度值裁剪(Value Clipping)按梯度值裁剪则是直接限制梯度值的范围,例如将梯度值限制在[−c,c][-c, c][−c,c]之间。这种方法虽然简单,但由于梯度方向可能被破坏,因此不如范数裁剪常用。
2.4 梯度裁剪的代码实现以下为PyTorch中实现梯度裁剪的代码示例:
from torch import nn # 定义模型 model = nn.TransformerDecoder(...) # 定义优化器 optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 在训练循环中 for inputs, targets in train_loader: # 前向传播 outputs = model(inputs) loss = criterion(outputs, targets) # 反向传播 optimizer.zero_grad() loss.backward() # 梯度裁剪 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 更新参数 optimizer.step()
python
运行
12345678910111213141516171819202122 2.5 梯度裁(续)裁剪的注意事项梯度裁剪虽然能有效防止梯度爆炸,但其参数设置需要谨慎。以下表格总结了梯度裁剪的关键参数设置建议:
参数名称建议取值范围说明max_norm1.0 - 5.0梯度范数的阈值,建议从较低值开始尝试阈值调整策略动态调整根据训练损失波动调整阈值梯度缩放因子自动计算避免手动缩放导致方向偏差三、辅助训练技巧:梯度缩放与混合精度训练
3.1 梯度缩放(Gradient Scaling)在Transformer训练中,不同层的梯度幅度可能存在较大差异。梯度缩放技术通过为每层梯度设置不同的缩放因子,平衡梯度的更新幅度。例如,使用梯度缩放因子γγγ,梯度更新为γ⋅gγ \cdot gγ⋅g,其中γγγ根据层深度动态调整。
3.2 混合精度训练(Mixed Precision Training)混合精度训练通过将部分计算转换为半精度浮点数(FP16),提高计算速度并减少内存占用。然而,FP16对梯度的表示精度较低,容易导致梯度溢出。因此,混合精度训练通常需要结合梯度缩放和梯度裁剪,以确保训练稳定性。
四、实战建议
学习率调度策略的选择:对于大规模Transformer模型,推荐使用余弦退火或随机梯度重启策略,以提高模型的收敛性和泛化能力。梯度裁剪的阈值设置:建议从max_norm=1.0开始尝试,逐步增加阈值,观察训练损失是否稳定。混合精度训练的配置:使用PyTorch的torch.cuda.amp.autocast和torch.cuda.amp.GradScaler实现混合精度训练,同时配合梯度缩放和梯度裁剪。结语
学习率调度和梯度裁剪是Transformer训练中的两大核心优化技巧。它们不仅能够显著提升模型的收敛速度和训练稳定性,还能有效应对大规模模型训练中的诸多挑战。本文通过理论分析、代码示例和实战建议,帮助读者全面掌握这些技巧,并在实际训练中灵活
运用。随着Transformer模型的不断发展,这些技巧将继续发挥重要作用,助力模型在更复杂的任务中取得更好的性能。
网址:Transformer训练技巧:从学习率调度到梯度裁剪 https://www.yuejiaxmz.com/news/view/1414712
相关内容
深度学习优化:提升训练效率与模型精度深度学习技巧:优化神经网络训练的策略
优化神经网络性能:高效的训练技巧
生成对抗网络的优化技巧:提升模型训练效率
深度神经网络训练的必知技巧
从工厂到生活:算法 × 深度学习,正在改写自动化的底层逻辑
CNN训练与优化技巧
深度学习加速秘籍:PyTorch训练循环优化全攻略
BAKU:一种用于多任务策略学习的高效 Transformer
深度学习提高trick小技巧
随便看看
最新动态分享
- 中医养生100条秘籍:掌握这些,健康长寿不是梦!
- 餐饮/旅游/美食网站源码
- 如何一键开启画中画模式:Chrome扩展终极指南
- 关于2025年湖南省优秀科普作品、科普项目立项名单的公示
- 和存在感薄弱妹妹一起的简单生活0.99安装包手游中文完整版下载安装2026最新版本
- 关于2026年湖南省科普项目(第一批)立项名单的公示
- 【Brain Puzzle: Tricky Quest】攻略・謎解きの答え:1~6ページ目のステージ
- 健康生活指南:简单实用的日常建议
- 全家适的健康生活指南,口腔到睡眠全覆盖,建议收藏慢慢看
- 【50条健康知识】践行健康生活方式在每一天
热点动态分享
- 145038
- 51843
- 45038
- 42424
- 40840
- 30842
- 25558
- 25474
- 21845
- 18548

