 介绍一种基于全卷积孪生网络的目标跟踪算法,该算法在ILSVRC15数据集上训练,实现端到端学习,超越实时帧率要求,性能卓越。论文提出了一种新的相似性学习方法,利用深度神经网络模拟相似性函数,通过孪生网络结构进行特征提取和比较,适用于大规模搜索区域。
介绍一种基于全卷积孪生网络的目标跟踪算法,该算法在ILSVRC15数据集上训练,实现端到端学习,超越实时帧率要求,性能卓越。论文提出了一种新的相似性学习方法,利用深度神经网络模拟相似性函数,通过孪生网络结构进行特征提取和比较,适用于大规模搜索区域。 2.φ\varphiφ 相当于特征提取器 2.1 Fully-convolutional Siamese architecture 网络结构如下图所示
1.zzz 表示样本图像(即目标)
2.xxx 表示待搜索图像
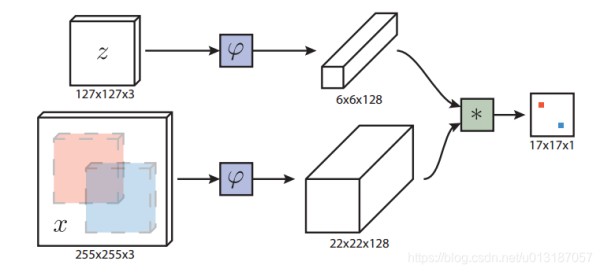 全卷积网络的优点是待搜索图像不需要与样本图像具有相同尺寸,可以为网络提供更大的搜索图像作为输入,然后在密集网格上计算所有平移窗口的相似度。本文的相似度函数使用互相关,公式如下(2)f(z,x)=φ(z)∗φ(x)+b1f(z,x)=\varphi(z) * \varphi(x) + b\mathcal 1 \tag{2}f(z,x)=φ(z)∗φ(x)+b1(2) 1.b1b\mathcal 1b1 表示在得分图中每个位置的取值
全卷积网络的优点是待搜索图像不需要与样本图像具有相同尺寸,可以为网络提供更大的搜索图像作为输入,然后在密集网格上计算所有平移窗口的相似度。本文的相似度函数使用互相关,公式如下(2)f(z,x)=φ(z)∗φ(x)+b1f(z,x)=\varphi(z) * \varphi(x) + b\mathcal 1 \tag{2}f(z,x)=φ(z)∗φ(x)+b1(2) 1.b1b\mathcal 1b1 表示在得分图中每个位置的取值2.上式可将 φ(z)\varphi(z)φ(z) 看成卷积核,在 φ(x)\varphi(x)φ(x) 上进行卷积跟踪时以上一帧目标位置为中心的搜索图像来计算响应得分图,将得分最大的位置乘以步长即可得到当前目标的位置。 2.2 Training with large search images 我们用判别方法来对正、负样本对进行训练,其逻辑损失定义如下:(3)l(y,v)=log(1+exp(−yv))\mathcal l(y,v)=log(1+exp(-yv))\tag{3}l(y,v)=log(1+exp(−yv))(3) 1.y∈(+1,−1)y\in(+1,-1)y∈(+1,−1) 表示真值
2.vvv 表示样本–搜索图像的实际得分
3.上式表示的正样本的概率为 11+e−v\frac{1}{1+e^{-v}}1+e−v1(sigmoid函数),负样本的概率为 1−11+e−v1-\frac{1}{1+e^{-v}}1−1+e−v1,则按交叉熵的公式很容易得到式 (3)(3)(3) 的loss训练时采用所有候选位置的平均loss来表示,公式如下:(4)L(y,v)=1D∑u∈Dl(y[u],v[u])L(y,v)=\frac{1}{\mathcal D}\sum_{u\in \mathcal D}\mathcal l(y[u],v[u])\tag{4}L(y,v)=D1u∈D∑l(y[u],v[u])(4) 1.D\mathcal DD 表示最后得到的 score map
2.uuu 表示 score map 中的所有位置训练的卷积参数 θ\thetaθ 通过SGD来最小化如下问题得到:(5)arg minθ=E(z,x,y) L(y,f(z,x;θ))arg\ \underset {\theta}{min}=\underset {(z,x,y)}{E}\ L(y,f(z,x;\theta))\tag{5}arg θmin=(z,x,y)E L(y,f(z,x;θ))(5)训练样本对 (z,x)(z,x)(z,x) 从标注的视频数据集得到,如下图所示
1.搜索区域 xxx 以目标区域 zzz 为中心
2.如果超出图像则用像素平均值填充,保持目标宽高比不变
3.训练时不考虑目标类别
4.网络的输入尺寸统一
 网络输出正负样本的确定:在输入搜索图像上(如255∗255255*255255∗255),只要和目标的距离不超过R,那就算正样本,否则就是负样本,用公式表示如下:(6)y[u]={+1if k∣∣u−c∣∣≤R−1otherwise.y[u]=\left\{amp;+1if k||u−c||≤Ramp;−1otherwise." role="presentation">amp;+1if k||u−c||≤Ramp;−1otherwise.\right.\tag{6}y[u]={+1if k∣∣u−c∣∣≤R−1otherwise.(6) 1.kkk 为网络的总步长
网络输出正负样本的确定:在输入搜索图像上(如255∗255255*255255∗255),只要和目标的距离不超过R,那就算正样本,否则就是负样本,用公式表示如下:(6)y[u]={+1if k∣∣u−c∣∣≤R−1otherwise.y[u]=\left\{amp;+1if k||u−c||≤Ramp;−1otherwise." role="presentation">amp;+1if k||u−c||≤Ramp;−1otherwise.\right.\tag{6}y[u]={+1if k∣∣u−c∣∣≤R−1otherwise.(6) 1.kkk 为网络的总步长2.ccc 为目标的中心
3.uuu 为score map的所有位置
4.RRR 为定义的半径 2.3 Practical considerations Dataset curation
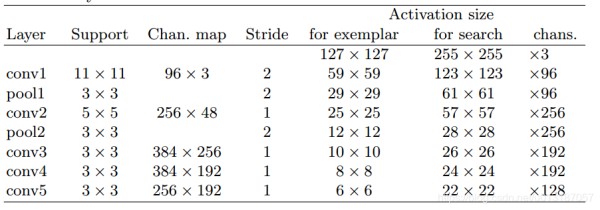
1.样本图像大小 127×127127\times 127127×127,搜索图像大小 255×255255\times255255×255
2.图像的缩放与填充如式所示:s(w+2p)×s(h+2p)=As(w+2p)\times s(h+2p)=As(w+2p)×s(h+2p)=A
3.从ILSVRC15的4500个视频中选出4417个视频,超过2,000,000个标注的跟踪框作为训练集Network architecture
1.前两个卷积层后有池化层;
2.每个卷积层后都有ReLU层(conv5除外);
3.每个线性层后都加上BN;
4.卷积层没有加padding;
 3. Experiments 3.1 Implementation details Training
3. Experiments 3.1 Implementation details Training1.梯度下降采用SGD
2.用高斯分布初始化参数
3.训练50个epoch,每个epoch有50,000个样本对
4.mini-batch等于8
5.学习率从10−210^{-2}10−2 衰减到 10−810^{-8}10−8Tracking
1.初始目标的特征提取 φ(z)\varphi(z)φ(z) 只计算一次
2.用双三次插值将score map从 17×1717 \times 1717×17 上采样到 272×272272 \times 272272×272
3.对目标进行5种尺度来搜索(1.025{−2,−1,0,1,2}1.025^{\left\{-2,-1,0,1,2\right\}}1.025{−2,−1,0,1,2})
4.目标图像在线不更新,因为对于CNN提取的是高层语义特征,不会像HOG或CN这些浅层特征苛求纹理相似度。(如跟踪目标是人,不论躺着或站着,CNN都能“认出来”这是人,而纹理特征如HOG或conv1可能完全无法匹配)
5.跟踪效率:3尺度86fps,5尺度58fps (NVIDIA GeForce GTX Titan X and an Intel Core i7-4790K at 4.0GHz) 3.2 Evalution 4. Cross-correlation与Correlation Filter Cross-correlation:适合特征分辨率较小的高层CNN,典型AlexNet的conv5,CNN特征提取部分更大更慢,滑窗检测计算量较大但没有边界效应,检测范围不受限,目标模型在线不更新,定位精度较低但更鲁棒。Correlation Filter:适合特征分辨率较大的低层CNN,典型AlexNet的conv2,CNN特征提取部分更小更快,模板更新和检测都可以在频域高效解决,CF速度快,但边界效应难以处理,目标模型在线更新,定位精度更高但容易被污染。

