交叉熵与KL散度和交叉熵之间的关系
在深度学习中,理解并合理选择损失函数很重要,例如分类任务使用交叉熵,回归任务使用均方误差 #生活技巧# #学习技巧# #深度学习技巧#
1.熵
熵的本质是香农信息量 l o g 1 p log\frac{1}{p} logp1
现有关于样本的两个概率分布 p p p和 q q q,其中 p p p为真实分布, q q q为非真实分布。按照真实分布 p p p来衡量识别一个样本所需要的编码长度的期望(即平均编码长度)为: H ( p ) = − ∑ i P ( i ) l o g P ( i ) H(p)=-\sum_i P(i)log P(i) H(p)=−i∑P(i)logP(i)
通用的说,熵被用于描述一个系统中的不确定性。放在信息论的语境里来说,就是一个事件所包含的信息量。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
可以看出,当两种取值的可能性相等时,不确定度最大,当p为0或1时,确定其一定不会或一定会发生,信息量(输出概率函数)为 H ( P ) = 0 H(P)=0 H(P)=0。
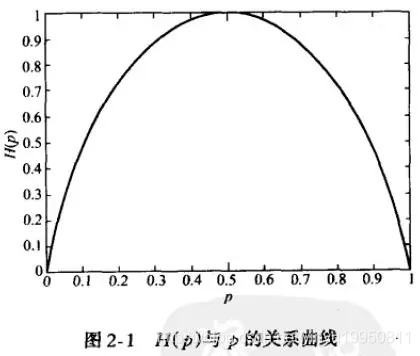
如果使用错误分布 q q q来表示来自真实分布 p p p的平均编码长度,则应该是: H ( p , q ) = − ∑ i P ( i ) l o g Q ( i ) H(p,q)=-\sum_i P(i)log\ Q(i) H(p,q)=−i∑P(i)log Q(i)
因为用 q q q来编码的样本来自分布 p p p,所以期望中的概率为 p ( i ) p(i) p(i), H ( p , q ) H(p,q) H(p,q)称之为交叉熵, 就是来衡量用特定的编码方案Q来对分布为P的信息进行编码时需要的最少的bits数.
比如含有4个字母(A,B,C,D)的数据集中,真实分布 p = ( 1 / 2 , 1 / 2 , 0 , 0 ) p=(1/2, 1/2, 0, 0) p=(1/2,1/2,0,0),即A和B出现的概率均为1/2,C和D出现的概率都为0。计算 H ( p ) H(p) H(p)为1,即只需要1位编码即可识别A和B。如果使用分布 Q = ( 1 / 4 , 1 / 4 , 1 / 4 , 1 / 4 ) Q=(1/4, 1/4, 1/4, 1/4) Q=(1/4,1/4,1/4,1/4)来编码则得到 H ( p , q ) = 2 H(p,q)=2 H(p,q)=2,即需要2位编码来识别 A A A和 B B B(当然还有 C C C和 D D D,尽管 C C C和 D D D并不会出现,因为真实分布 p p p中C和D出现的概率为0,这里就钦定概率为0的事件不会发生啦)。
2.KL散度
可以看到上例中根据非真实分布 q q q得到的平均编码长度 H ( p , q ) H(p,q) H(p,q)和根据真实分布 p p p得到的平均编码长度 H ( p ) H(p) H(p)。事实上,根据Gibbs’ inequality可知, H ( p , q ) > = H ( p ) H(p,q)>=H(p) H(p,q)>=H(p)恒成立,当 q q q为真实分布 p p p时,取等号。
对于固定的 p p p, H ( p , q ) H(p,q) H(p,q)将随着 q q q变得与 p p p越来越不同而增长。 而如果 p p p没有固定,很难将 H ( p , q ) H(p,q) H(p,q)解释为差异的绝对量度,因为它随着 p p p的熵增长。所以我们使用另一种度量方式来度量两个分布的差异性,将由 q q q得到的平均编码长度比由 p p p得到的平均编码长度多出的bit数称为“相对熵”,也叫做KL散度(Kullback–Leibler divergence):
D K L ( p ∣ ∣ q ) = H ( p , q ) − H ( p ) = ∑ i P ( i ) ∗ ( l o g P ( i ) − l o g Q ( i ) ) D_{KL}(p||q)=H(p,q)-H(p)=\sum_{i}^{} P(i)*(logP(i)-logQ(i)) DKL(p∣∣q)=H(p,q)−H(p)=i∑P(i)∗(logP(i)−logQ(i))
它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若两者相同则KL散度为0,而交叉熵不为0,而是等于 p p p的熵。
KL散度的非对称性注意,KL散度的非对称性,一些同学把K-L散度看作是不同分布之间距离的度量。这是不对的,因为从K-L散度的计算公式就可以看出它不符合对称性(距离度量应该满足对称性),即$D_{KL}(P||Q) \neq D K L ( Q ∣ ∣ P ) D_{KL}(Q||P) DKL(Q∣∣P)。也就是说用 p p p近似 q q q和用 q q q近似 p p p,二者所得的损失信息并不是一样的。
比如TD-IDF算法就可以理解为相对熵的应用:词频在整个语料库的分布与词频在具体文档中分布之间的差异性。
KL散度与交叉熵的关系 H ( p , q ) = − ∑ P l o g Q = = − ∑ P l o g P + ∑ P l o g P − ∑ P l o g Q H(p,q)=-\sum P logQ==-\sum P logP+\sum P logP-\sum P logQ H(p,q)=−∑PlogQ==−∑PlogP+∑PlogP−∑PlogQ
= H ( P ) + ∑ P l o g P / Q = H ( P ) + D K L ( P ∣ ∣ Q ) =H(P)+\sum P logP/Q=H(P)+D_{KL}(P||Q) =H(P)+∑PlogP/Q=H(P)+DKL(P∣∣Q)
可见,交叉熵就是真值分布的熵与KL散度的和,而真值的熵是确定的,与模型的参数 θ \theta θ无关,所以梯度下降求导时, ∇ H ( P , Q ) = ∇ D K L ( P ∣ ∣ Q ) \nabla H(P,Q)=\nabla D_{KL}(P||Q) ∇H(P,Q)=∇DKL(P∣∣Q),即最小化交叉熵与最小化KL散度是一样的;
最大似然估计
交叉熵经常出现在(神经网络)机器学习的损失函数中。 p p p表示真实的分布, q q q则为训练后的模型的预测标记分布。例如,在分类问题中,通常使用交叉熵损失度量标签的真实分布和由分类器预测的分布之间的差异。每个数据点的真实分布将概率1分配给该数据点所属的类,将0分配给所有其他类。在这种情况下,交叉熵与负对数似然成正比,最小化负对数似然等价于最小化交叉熵:
极大似然估计:
θ ^ = a r g m a x θ ∏ i = 1 N q ( x i ∣ θ ) \hat{\theta}=arg max_{\theta}\prod_{i=1}^{N}q(x_i | \theta) θ^=argmaxθ∏i=1Nq(xi∣θ)
等价于最小化负对数似然
θ ^ = a r g m i n θ − ∑ i = 1 N l o g ( q ( x i ∣ θ ) ) \hat{\theta}=arg min_{\theta}-\sum_{i=1}^{N}log(q(x_i | \theta)) θ^=argminθ−∑i=1Nlog(q(xi∣θ))
= a r g m i n θ − ∑ x ∈ X p ( x ) l o g ( q ( x ∣ θ ) ) =arg min_{\theta}-\sum_{x \in X} p(x)log(q(x | \theta)) =argminθ−∑x∈Xp(x)log(q(x∣θ))
= a r g m i n θ H ( p , q ) =arg min_{\theta}H(p,q) =argminθH(p,q)
交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。??
从优化模型参数角度来说,最小化交叉熵,NLL,KL散度这3种方式对模型参数的更新来说是一样的。从这点来看也解释了为什么在深度学习中交叉熵是非常常用的损失函数的原因了。
参考资料:
如何通俗的解释交叉熵与相对熵?Why do we use Kullback-Leibler divergence rather than cross entropy in the t-SNE objective function?网址:交叉熵与KL散度和交叉熵之间的关系 https://www.yuejiaxmz.com/news/view/928940
相关内容
相对熵与KL散度:推荐系统与个性化优化1.背景介绍 随着互联网的普及和数据的崛起,人工智能技术已经成为了我们生活中不可或熵增定律:对个人成长的启发
熵基科技接入DeepSeek,塑造未来智慧空间新范式
基于熵值法和SBRB的智能家居多人活动识别方法技术
Python实现熵值法计算权重
物联网行业“奥斯卡”,熵基科技斩获双料大奖
Python熵权法确定权重
面试笔试整理3:深度学习机器学习面试问题准备(必会)
心流=熵减活动=无序到有序
御熵能源app下载
随便看看
最新动态分享
- 任职知名大厂、年薪超50万仍想“多赚钱改善生活”,3名研究生兼职当黑客被抓
- 在女性黑客松上,看见AI硬件的另一种可能
- 境外黑客制作假页面窃取敏感数据
- 安联人寿遭黑客攻击,客户信息被泄露
- 某企员工用搜索引擎下载软件 不慎落入境外黑客窃密陷阱
- 亚马逊报告:黑客利用AI工具五周内攻破全球超600个防火墙
- 从0到1孵化AI创意,黑客松顶尖高校联赛落下帷幕
- 一场黑客松背后,上海正形成更多AI创业“连接器”
- 工作模拟游戏推荐哪个 最新工作模拟游戏精选
- 黑客游戏哪个最好玩 十大必玩黑客游戏排行榜
热点动态分享
- 143817
- 44412
- 44002
- 39583
- 37259
- 29003
- 24200
- 24049
- 20350
- 17567

